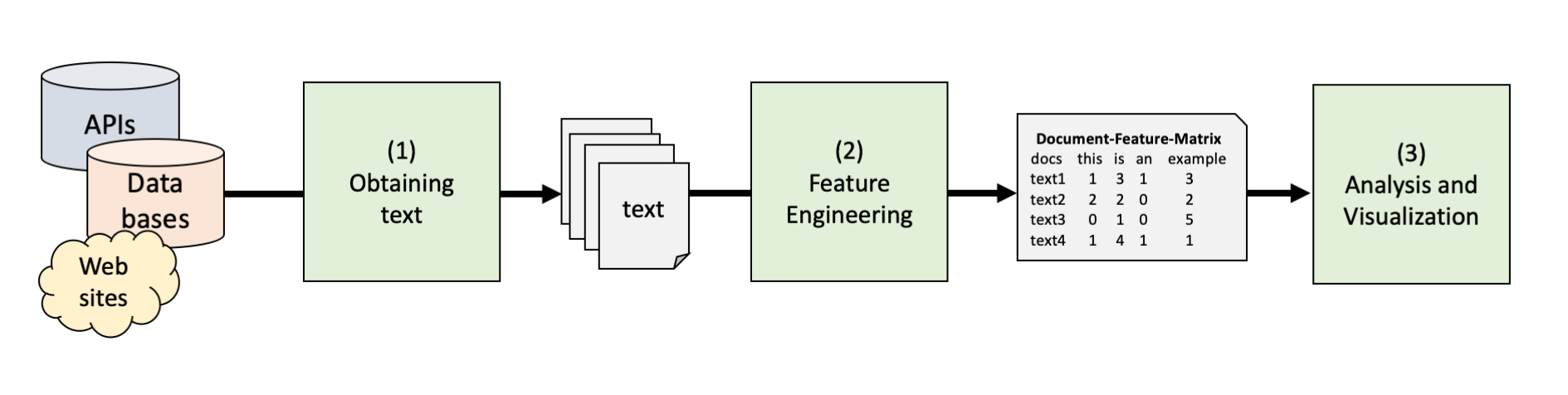
Basics of Automated Text Analysis and Dictionary Approaches
Week 2: Wrangling Text and Classification with Wordlists
Largest encyclopedias in the world
Encyclopedia Britannica
- maintained by about 100 full-time editors and more than 4,000 contributors
- 2010 version of the 15th edition, which spans 32 volumes and 32,640 pages, was the last printed edition
- Today, 40 million words on half a million topics

Wikipedia
- Biggest encyclopedia worldwide
- more than 280,000 active editors and 110,461,483 registered users
- ~61 million articles
Automated text analysis…
…with dictionaries!
Basic Text Analysis
Before we start to classify unlabeled text, we often engage in what we call “basic text analysis”
The first goal is find ways to represent texts in numerical frameworks
Then, we often want to conduct simple descriptive analyses on the texts (e.g., which words are used most often)
A challenge at the beginning
Texts are strings composed of words, spaces, numbers, and punctation.
Handling this type of complex, at times messy, data requires some thought and effort.
Problem: Algorithms process numbers, they do not read text!
Consider the following string, representing a (very) short text:

Tokenization
Separating based on white space or specific “regular expressions” sounds correct intuitively, but is not a very principled approach
More generally, tokenization means:
- taking an input (e.g., a string of characters that represent natural language) and
- a token type (a meaningful unit of text, such as a character, word, or sentence)
- and splitting the input (string) into pieces (tokens) that correspond to the type (e.g., word)

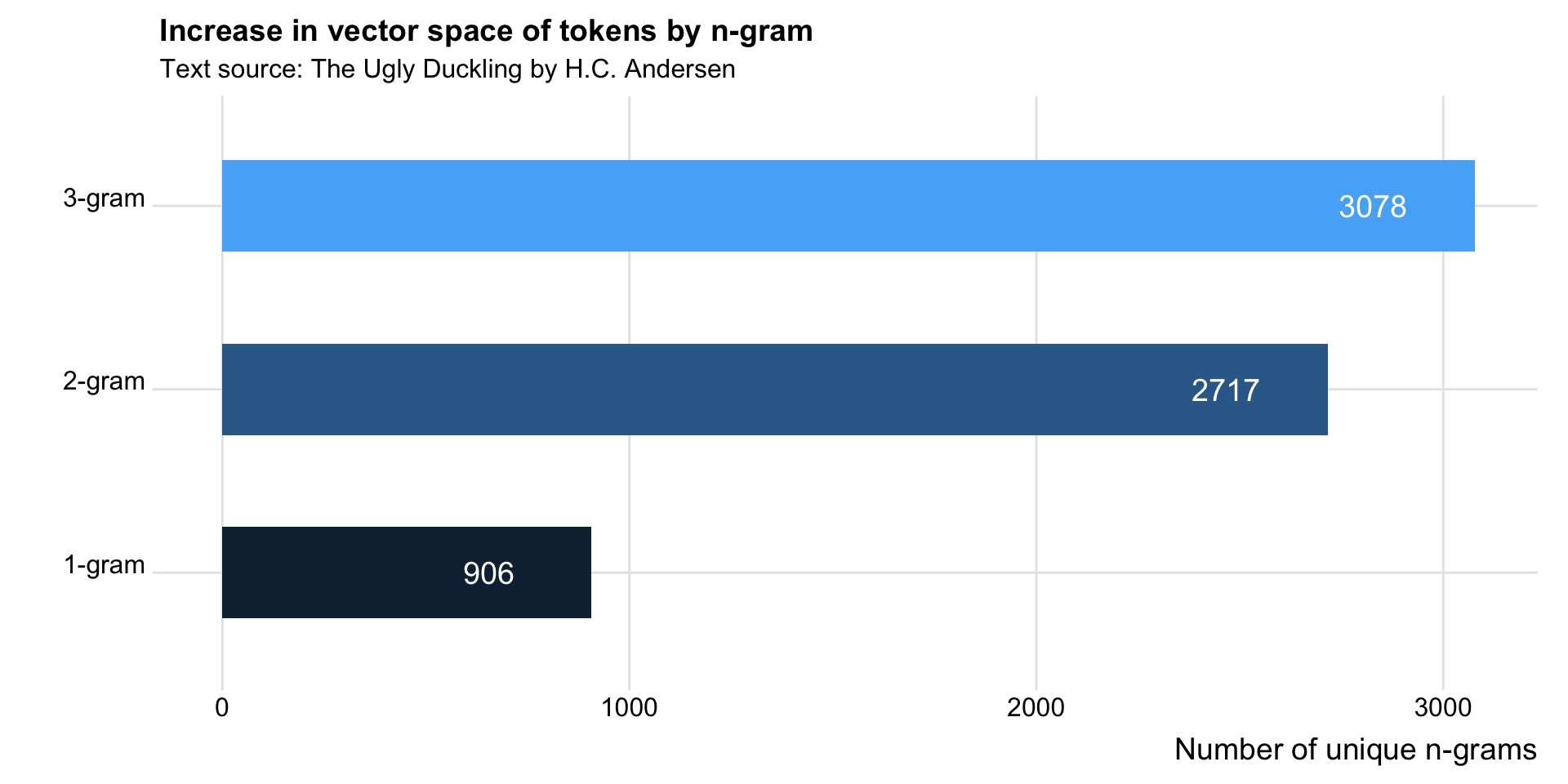
Logic of n-grams
Using a higher value for
nkeeps more information, but the vector space of tokens increases dramatically, corresponding to a reduction in token counts.The longer the n-gram, the larger the list of unique combinations, which leads to a worse data scarcity problems, so even more attention must be paid to feature selection and/or trimming
A tidy format for text analysis
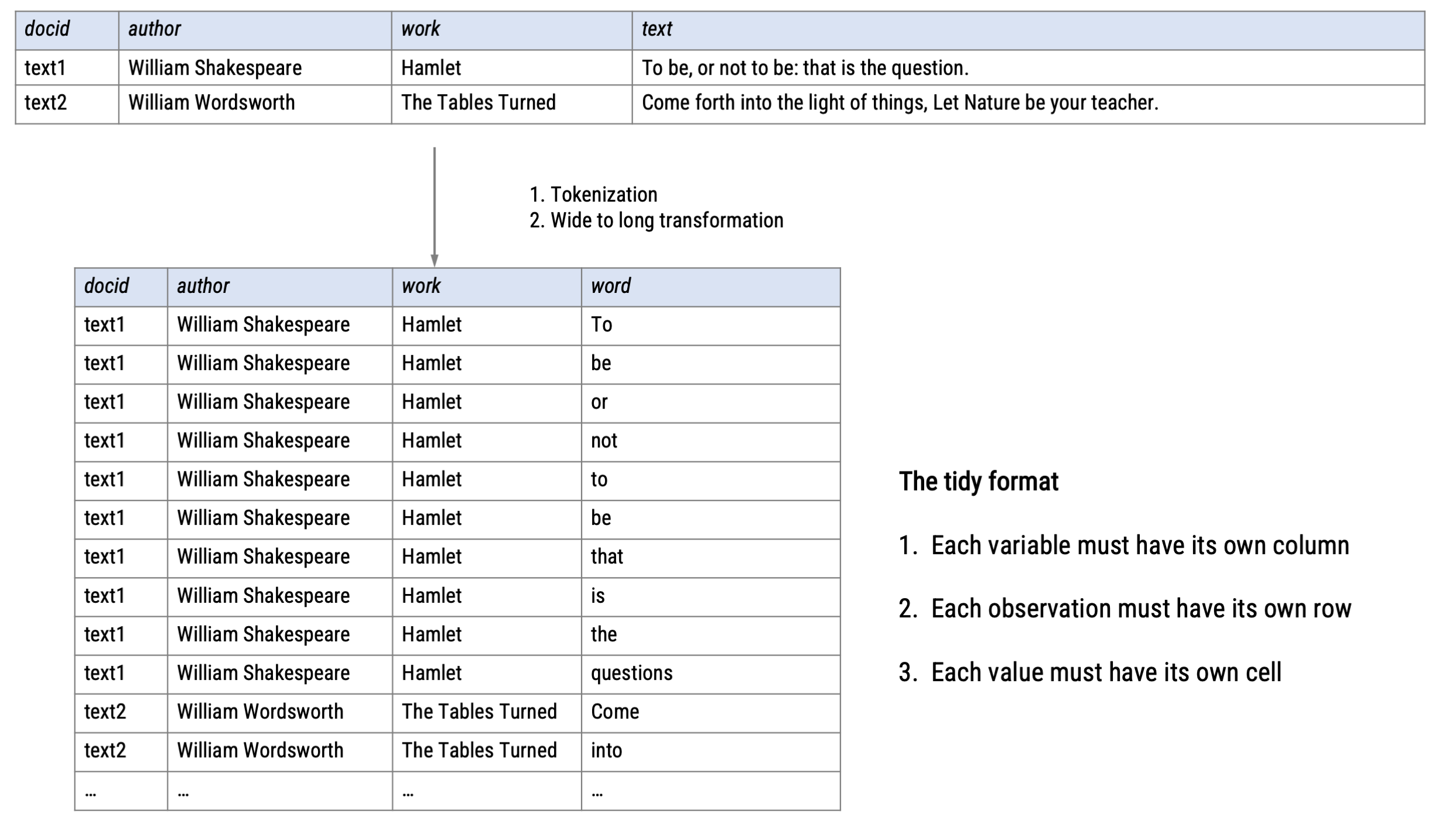
From tokens to numbers
Reminder: In automated text classification, we need to break text into tokens and then represent these tokens as numbers, so that a computer can read them:
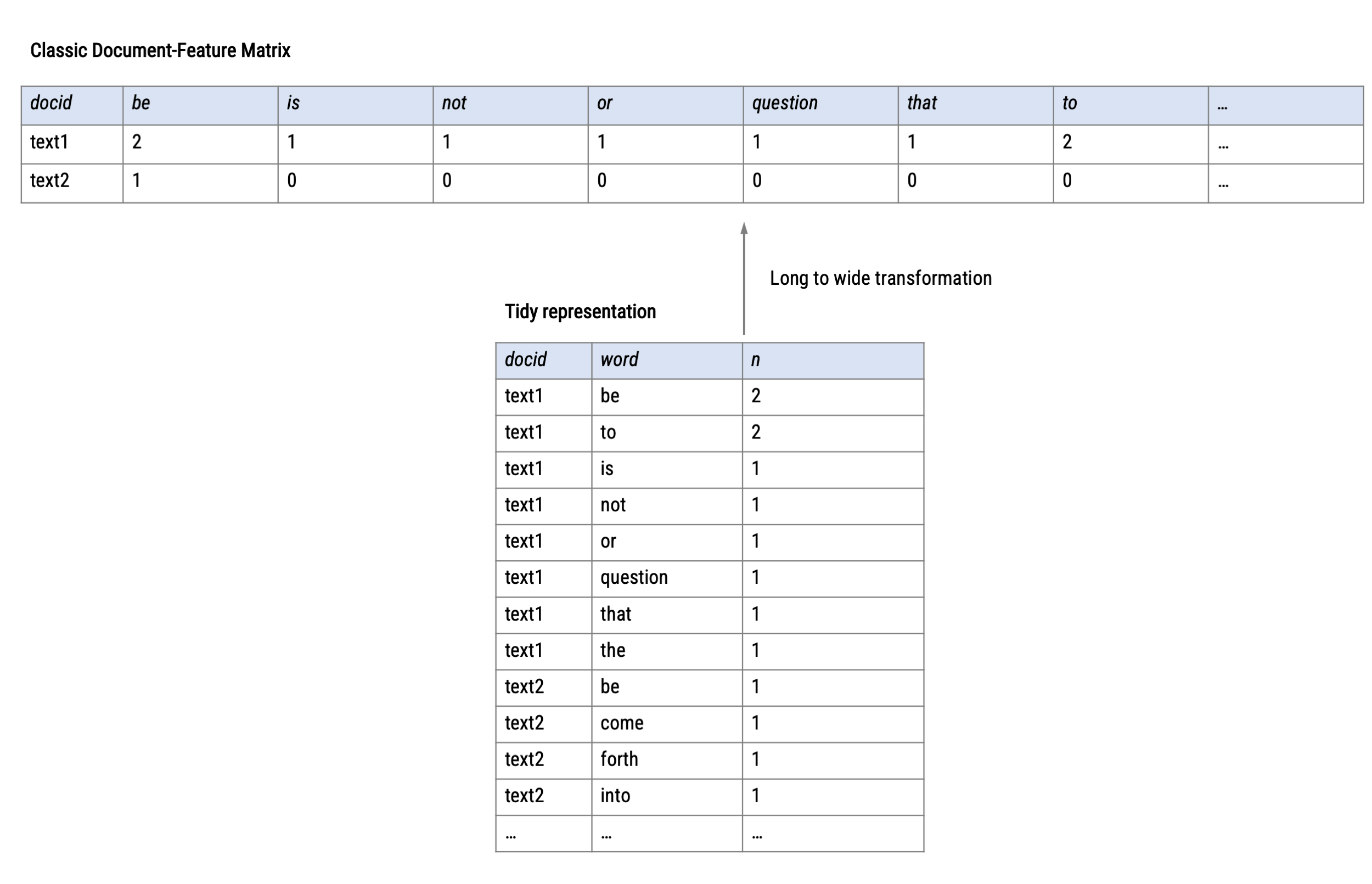
Tidy format vs. DTM
The State of the Union Speeches Corpus
For the following explanation, we are going to look at a more realistic corpus of texts.
This corpus contains all State of the Union (SOTU) speeches of U.S. presidents from 1790 to 2020.

A speech by Barack Obama in 2009
sotu_text |>
filter(president == "Barack Obama" & year == "2009") |> # <-- filter based on name and year
select(text) |> # <-- select only text
as.character() |> # <-- transform to characters
writeLines() # <-- print all linesMadam Speaker, Mr. Vice President, Members of Congress, the First Lady of the United States--she's around here somewhere: I have come here tonight not only to address the distinguished men and women in this great Chamber, but to speak frankly and directly to the men and women who sent us here.
I know that for many Americans watching right now, the state of our economy is a concern that rises above all others, and rightly so. If you haven't been personally affected by this recession, you probably know someone who has: a friend, a neighbor, a member of your family. You don't need to hear another list of statistics to know that our economy is in crisis, because you live it every day. It's the worry you wake up with and the source of sleepless nights. It's the job you thought you'd retire from but now have lost, the business you built your dreams upon that's now hanging by a thread, the college acceptance letter your child had to put back in the envelope. The impact of this recession is real, and it is everywhere.
But while our economy may be weakened and our confidence shaken, though we are living through difficult and uncertain times, tonight I want every American to know this: We will rebuild, we will recover, and the United States of America will emerge stronger than before.
The weight of this crisis will not determine the destiny of this Nation. The answers to our problems don't lie beyond our reach. They exist in our laboratories and our universities, in our fields and our factories, in the imaginations of our entrepreneurs and the pride of the hardest working people on Earth. Those qualities that have made America the greatest force of progress and prosperity in human history, we still possess in ample measure. What is required now is for this country to pull together, confront boldly the challenges we face, and take responsibility for our future once more.
Now, if we're honest with ourselves, we'll admit that for too long, we have not always met these responsibilities as a Government or as a people. I say this not to lay blame or to look backwards, but because it is only by understanding how we arrived at this moment that we'll be able to lift ourselves out of this predicament.
The fact is, our economy did not fall into decline overnight, nor did all of our problems begin when the housing market collapsed or the stock market sank. We have known for decades that our survival depends on finding new sources of energy, yet we import more oil today than ever before. The cost of health care eats up more and more of our savings each year, yet we keep delaying reform. Our children will compete for jobs in a global economy that too many of our schools do not prepare them for. And though all these challenges went unsolved, we still managed to spend more money and pile up more debt, both as individuals and through our Government, than ever before.
In other words, we have lived through an era where too often short-term gains were prized over long-term prosperity, where we failed to look beyond the next payment, the next quarter, or the next election. A surplus became an excuse to transfer wealth to the wealthy instead of an opportunity to invest in our future. Regulations were gutted for the sake of a quick profit at the expense of a healthy market. People bought homes they knew they couldn't afford from banks and lenders who pushed those bad loans anyway. And all the while, critical debates and difficult decisions were put off for some other time, on some other day. Well, that day of reckoning has arrived, and the time to take charge of our future is here.
Now is the time to act boldly and wisely to not only revive this economy, but to build a new foundation for lasting prosperity. Now is the time to jump-start job creation, restart lending, and invest in areas like energy, health care, and education that will grow our economy, even as we make hard choices to bring our deficit down. That is what my economic agenda is designed to do, and that is what I'd like to talk to you about tonight. It's an agenda that begins with jobs.
As soon as I took office, I asked this Congress to send me a recovery plan by President's Day that would put people back to work and put money in their pockets, not because I believe in bigger Government--I don't--not because I'm not mindful of the massive debt we've inherited--I am. I called for action because the failure to do so would have cost more jobs and caused more hardship. In fact, a failure to act would have worsened our long-term deficit by assuring weak economic growth for years. And that's why I pushed for quick action. And tonight I am grateful that this Congress delivered and pleased to say that the American Recovery and Reinvestment Act is now law.
Over the next 2 years, this plan will save or create 3.5 million jobs. More than 90 percent of these jobs will be in the private sector: jobs rebuilding our roads and bridges, constructing wind turbines and solar panels, laying broadband and expanding mass transit.
Because of this plan, there are teachers who can now keep their jobs and educate our kids, health care professionals can continue caring for our sick. There are 57 police officers who are still on the streets of Minneapolis tonight because this plan prevented the layoffs their department was about to make. Because of this plan, 95 percent of working households in America will receive a tax cut; a tax cut that you will see in your paychecks beginning on April 1st. Because of this plan, families who are struggling to pay tuition costs will receive a $2,500 tax credit for all 4 years of college, and Americans who have lost their jobs in this recession will be able to receive extended unemployment benefits and continued health care coverage to help them weather this storm.
Now, I know there are some in this Chamber and watching at home who are skeptical of whether this plan will work, and I understand that skepticism. Here in Washington, we've all seen how quickly good intentions can turn into broken promises and wasteful spending. And with a plan of this scale comes enormous responsibility to get it right.
And that's why I've asked Vice President Biden to lead a tough, unprecedented oversight effort; because nobody messes with Joe. I--am I right? They don't mess with him. I have told each of my Cabinet, as well as mayors and Governors across the country, that they will be held accountable by me and the American people for every dollar they spend. I've appointed a proven and aggressive Inspector General to ferret out any and all cases of waste and fraud. And we have created a new web site called recovery.gov, so that every American can find out how and where their money is being spent.
So the recovery plan we passed is the first step in getting our economy back on track. But it is just the first step. Because even if we manage this plan flawlessly, there will be no real recovery unless we clean up the credit crisis that has severely weakened our financial system.
I want to speak plainly and candidly about this issue tonight, because every American should know that it directly affects you and your family's well-being. You should also know that the money you've deposited in banks across the country is safe, your insurance is secure, you can rely on the continued operation of our financial system. That's not the source of concern. The concern is that if we do not restart lending in this country, our recovery will be choked off before it even begins.
You see, the flow of credit is the lifeblood of our economy. The ability to get a loan is how you finance the purchase of everything from a home to a car to a college education, how stores stock their shelves, farms buy equipment, and businesses make payroll.
But credit has stopped flowing the way it should. Too many bad loans from the housing crisis have made their way onto the books of too many banks. And with so much debt and so little confidence, these banks are now fearful of lending out any more money to households, to businesses, or even to each other. And when there is no lending, families can't afford to buy homes or cars, so businesses are forced to make layoffs. Our economy suffers even more, and credit dries up even further. That is why this administration is moving swiftly and aggressively to break this destructive cycle, to restore confidence, and restart lending. And we will do so in several ways.
First, we are creating a new lending fund that represents the largest effort ever to help provide auto loans, college loans, and small-business loans to the consumers and entrepreneurs who keep this economy running.
Second, we have launched a housing plan that will help responsible families facing the threat of foreclosure lower their monthly payments and refinance their mortgages. It's a plan that won't help speculators or that neighbor down the street who bought a house he could never hope to afford, but it will help millions of Americans who are struggling with declining home values; Americans who will now be able to take advantage of the lower interest rates that this plan has already helped to bring about. In fact, the average family who refinances today can save nearly $2,000 per year on their mortgage.
Third, we will act with the full force of the Federal Government to ensure that the major banks that Americans depend on have enough confidence and enough money to lend even in more difficult times. And when we learn that a major bank has serious problems, we will hold accountable those responsible, force the necessary adjustments, provide the support to clean up their balance sheets, and assure the continuity of a strong, viable institution that can serve our people and our economy.
Now, I understand that on any given day, Wall Street may be more comforted by an approach that gives bank bailouts with no strings attached and that holds nobody accountable for their reckless decisions. But such an approach won't solve the problem, and our goal is to quicken the day when we restart lending to the American people and American business and end this crisis once and for all.
And I intend to hold these banks fully accountable for the assistance they receive, and this time, they will have to clearly demonstrate how taxpayer dollars result in more lending for the American taxpayer. This time, CEOs won't be able to use taxpayer money to pad their paychecks or buy fancy drapes or disappear on a private jet. Those days are over.
Still, this plan will require significant resources from the Federal Government--and, yes, probably more than we've already set aside. But while the cost of action will be great, I can assure you that the cost of inaction will be far greater, for it could result in an economy that sputters along for not months or years, but perhaps a decade. That would be worse for our deficit, worse for business, worse for you, and worse for the next generation. And I refuse to let that happen.
Now, I understand that when the last administration asked this Congress to provide assistance for struggling banks, Democrats and Republicans alike were infuriated by the mismanagement and the results that followed. So were the American taxpayers; so was I. So I know how unpopular it is to be seen as helping banks right now, especially when everyone is suffering in part from their bad decisions. I promise you, I get it.
But I also know that in a time of crisis, we cannot afford to govern out of anger or yield to the politics of the moment. My job--our job is to solve the problem. Our job is to govern with a sense of responsibility. I will not send--I will not spend a single penny for the purpose of rewarding a single Wall Street executive, but I will do whatever it takes to help the small business that can't pay its workers or the family that has saved and still can't get a mortgage. That's what this is about. It's not about helping banks; it's about helping people.
It's not about helping banks; it's about helping people. Because when credit is available again, that young family can finally buy a new home. And then some company will hire workers to build it. And then those workers will have money to spend. And if they can get a loan too, maybe they'll finally buy that car or open their own business. Investors will return to the market, and American families will see their retirement secured once more. Slowly but surely, confidence will return and our economy will recover.
So I ask this Congress to join me in doing whatever proves necessary, because we cannot consign our Nation to an open-ended recession. And to ensure that a crisis of this magnitude never happens again, I ask Congress to move quickly on legislation that will finally reform our outdated regulatory system. It is time to put in place tough, new, commonsense rules of the road so that our financial market rewards drive and innovation, and punishes shortcuts and abuse.
The recovery plan and the financial stability plan are the immediate steps we're taking to revive our economy in the short term. But the only way to fully restore America's economic strength is to make the long-term investments that will lead to new jobs, new industries, and a renewed ability to compete with the rest of the world. The only way this century will be another American century is if we confront at last the price of our dependence on oil and the high cost of health care, the schools that aren't preparing our children and the mountain of debt they stand to inherit. That is our responsibility.
In the next few days, I will submit a budget to Congress. So often, we've come to view these documents as simply numbers on a page or a laundry list of programs. I see this document differently. I see it as a vision for America, as a blueprint for our future.
My budget does not attempt to solve every problem or address every issue. It reflects the stark reality of what we've inherited, a trillion-dollar deficit, a financial crisis, and a costly recession. Given these realities, everyone in this Chamber, Democrats and Republicans, will have to sacrifice some worthy priorities for which there are no dollars. And that includes me. But that does not mean we can afford to ignore our long-term challenges. I reject the view that says our problems will simply take care of themselves, that says Government has no role in laying the foundation for our common prosperity.
For history tells a different story. History reminds us that at every moment of economic upheaval and transformation, this Nation has responded with bold action and big ideas. In the midst of Civil War, we laid railroad tracks from one coast to another that spurred commerce and industry. From the turmoil of the Industrial Revolution came a system of public high schools that prepared our citizens for a new age. In the wake of war and depression, the GI bill sent a generation to college and created the largest middle class in history. And a twilight struggle for freedom led to a nation of highways, an American on the Moon, and an explosion of technology that still shapes our world. In each case, Government didn't supplant private enterprise; it catalyzed private enterprise. It created the conditions for thousands of entrepreneurs and new businesses to adapt and to thrive.
We are a nation that has seen promise amid peril and claimed opportunity from ordeal. Now we must be that nation again, and that is why, even as it cuts back on programs we don't need, the budget I submit will invest in the three areas that are absolutely critical to our economic future: energy, health care, and education.
It begins with energy. We know the country that harnesses the power of clean, renewable energy will lead the 21st century. And yet, it is China that has launched the largest effort in history to make their economy energy efficient. We invented solar technology, but we've fallen behind countries like Germany and Japan in producing it. New plug-in hybrids roll off our assembly lines, but they will run on batteries made in Korea. Well, I do not accept a future where the jobs and industries of tomorrow take root beyond our borders, and I know you don't either. It is time for America to lead again.
Thanks to our recovery plan, we will double this Nation's supply of renewable energy in the next 3 years. We've also made the largest investment in basic research funding in American history, an investment that will spur not only new discoveries in energy but breakthroughs in medicine and science and technology.
We will soon lay down thousands of miles of power lines that can carry new energy to cities and towns across this country. And we will put Americans to work making our homes and buildings more efficient so that we can save billions of dollars on our energy bills.
But to truly transform our economy, to protect our security, and save our planet from the ravages of climate change, we need to ultimately make clean, renewable energy the profitable kind of energy. So I ask this Congress to send me legislation that places a market-based cap on carbon pollution and drives the production of more renewable energy in America. That's what we need. And to support that innovation, we will invest $15 billion a year to develop technologies like wind power and solar power, advanced biofuels, clean coal, and more efficient cars and trucks built right here in America.
Speaking of our auto industry, everyone recognizes that years of bad decisionmaking and a global recession have pushed our automakers to the brink. We should not, and will not, protect them from their own bad practices. But we are committed to the goal of a retooled, reimagined auto industry that can compete and win. Millions of jobs depend on it; scores of communities depend on it. And I believe the Nation that invented the automobile cannot walk away from it.
Now, none of this will come without cost, nor will it be easy. But this is America. We don't do what's easy. We do what's necessary to move this country forward.
And for that same reason, we must also address the crushing cost of health care. This is a cost that now causes a bankruptcy in America every 30 seconds. By the end of the year, it could cause 1.5 million Americans to lose their homes. In the last 8 years, premiums have grown four times faster than wages. And in each of these years, 1 million more Americans have lost their health insurance. It is one of the major reasons why small businesses close their doors and corporations ship jobs overseas. And it's one of the largest and fastest growing parts of our budget. Given these facts, we can no longer afford to put health care reform on hold. We can't afford to do it. It's time.
Already, we've done more to advance the cause of health care reform in the last 30 days than we've done in the last decade. When it was days old, this Congress passed a law to provide and protect health insurance for 11 million American children whose parents work full time. Our recovery plan will invest in electronic health records, a new technology that will reduce errors, bring down costs, ensure privacy, and save lives. It will launch a new effort to conquer a disease that has touched the life of nearly every American, including me, by seeking a cure for cancer in our time. And it makes the largest investment ever in preventive care, because that's one of the best ways to keep our people healthy and our costs under control.
This budget builds on these reforms. It includes a historic commitment to comprehensive health care reform, a down payment on the principle that we must have quality, affordable health care for every American. It's a commitment that's paid for in part by efficiencies in our system that are long overdue. And it's a step we must take if we hope to bring down our deficit in the years to come.
Now, there will be many different opinions and ideas about how to achieve reform, and that's why I'm bringing together businesses and workers, doctors and health care providers, Democrats and Republicans to begin work on this issue next week.
I suffer no illusions that this will be an easy process. Once again, it will be hard. But I also know that nearly a century after Teddy Roosevelt first called for reform, the cost of our health care has weighed down our economy and our conscience long enough. So let there be no doubt: Health care reform cannot wait, it must not wait, and it will not wait another year.
The third challenge we must address is the urgent need to expand the promise of education in America. In a global economy where the most valuable skill you can sell is your knowledge, a good education is no longer just a pathway to opportunity, it is a prerequisite. Right now, three-quarters of the fastest growing occupations require more than a high school diploma. And yet, just over half of our citizens have that level of education. We have one of the highest high school dropout rates of any industrialized nation, and half of the students who begin college never finish.
This is a prescription for economic decline, because we know the countries that out-teach us today will outcompete us tomorrow. That is why it will be the goal of this administration to ensure that every child has access to a complete and competitive education, from the day they are born to the day they begin a career. That is a promise we have to make to the children of America.
Already, we've made historic investment in education through the economic recovery plan. We've dramatically expanded early childhood education and will continue to improve its quality, because we know that the most formative learning comes in those first years of life. We've made college affordable for nearly 7 million more students--7 million. And we have provided the resources necessary to prevent painful cuts and teacher layoffs that would set back our children's progress.
But we know that our schools don't just need more resources, they need more reform. And that is why this budget creates new teachers--new incentives for teacher performance, pathways for advancement, and rewards for success. We'll invest in innovative programs that are already helping schools meet high standards and close achievement gaps, and we will expand our commitment to charter schools.
It is our responsibility as lawmakers and as educators to make this system work. But it is the responsibility of every citizen to participate in it. So tonight I ask every American to commit to at least 1 year or more of higher education or career training. This can be community college or a 4-year school, vocational training or an apprenticeship. But whatever the training may be, every American will need to get more than a high school diploma.
And dropping out of high school is no longer an option. It's not just quitting on yourself, it's quitting on your country, and this country needs and values the talents of every American. That's why we will support--we will provide the support necessary for all young Americans to complete college and meet a new goal. By 2020, America will once again have the highest proportion of college graduates in the world. That is a goal we can meet. That's a goal we can meet.
Now, I know that the price of tuition is higher than ever, which is why if you are willing to volunteer in your neighborhood or give back to your community or serve your country, we will make sure that you can afford a higher education. And to encourage a renewed spirit of national service for this and future generations, I ask Congress to send me the bipartisan legislation that bears the name of Senator Orrin Hatch, as well as an American who has never stopped asking what he can do for his country, Senator Edward Kennedy.
These education policies will open the doors of opportunity for our children, but it is up to us to ensure they walk through them. In the end, there is no program or policy that can substitute for a parent, for a mother or father who will attend those parent-teacher conferences or help with homework or turn off the TV, put away the video games, read to their child. I speak to you not just as a President, but as a father, when I say that responsibility for our children's education must begin at home. That is not a Democratic issue or a Republican issue; that's an American issue.
There is, of course, another responsibility we have to our children. And that's the responsibility to ensure that we do not pass on to them a debt they cannot pay. That is critical. I agree, absolutely. See, I know we can get some consensus in here. [Laughter] With the deficit we inherited, the cost of the crisis we face, and the long-term challenges we must meet, it has never been more important to ensure that as our economy recovers, we do what it takes to bring this deficit down. That is critical.
Now, I'm proud that we passed a recovery plan free of earmarks, and I want to pass a budget next year that ensures that each dollar we spend reflects only our most important national priorities.
And yesterday I held a fiscal summit where I pledged to cut the deficit in half by the end of my first term in office. My administration has also begun to go line by line through the Federal budget in order to eliminate wasteful and ineffective programs. As you can imagine, this is a process that will take some time. But we have already identified $2 trillion in savings over the next decade.
In this budget, we will end education programs that don't work and end direct payments to large agribusiness that don't need them. We'll eliminate the no-bid contracts that have wasted billions in Iraq and reform our defense budget so that we're not paying for cold war-era weapons systems we don't use. We will root out the waste and fraud and abuse in our Medicare program that doesn't make our seniors any healthier. We will restore a sense of fairness and balance to our Tax Code by finally ending the tax breaks for corporations that ship our jobs overseas.
In order to save our children from a future of debt, we will also end the tax breaks for the wealthiest 2 percent of Americans. Now, let me be clear--let me be absolutely clear, because I know you'll end up hearing some of the same claims that rolling back these tax breaks means a massive tax increase on the American people: If your family earns less than $250,000 a year, a quarter million dollars a year, you will not see your taxes increased a single dime. I repeat: Not one single dime. In fact--not a dime--in fact, the recovery plan provides a tax cut--that's right, a tax cut--for 95 percent of working families. And by the way, these checks are on the way.
Now, to preserve our long-term fiscal health, we must also address the growing costs in Medicare and Social Security. Comprehensive health care reform is the best way to strengthen Medicare for years to come. And we must also begin a conversation on how to do the same for Social Security, while creating tax-free universal savings accounts for all Americans.
Finally, because we're also suffering from a deficit of trust, I am committed to restoring a sense of honesty and accountability to our budget. That is why this budget looks ahead 10 years and accounts for spending that was left out under the old rules. And for the first time, that includes the full cost of fighting in Iraq and Afghanistan. For 7 years, we have been a nation at war. No longer will we hide its price.
Along with our outstanding national security team, I'm now carefully reviewing our policies in both wars, and I will soon announce a way forward in Iraq that leaves Iraq to its people and responsibly ends this war.
And with our friends and allies, we will forge a new and comprehensive strategy for Afghanistan and Pakistan to defeat Al Qaida and combat extremism, because I will not allow terrorists to plot against the American people from safe havens halfway around the world. We will not allow it.
As we meet here tonight, our men and women in uniform stand watch abroad and more are readying to deploy. To each and every one of them and to the families who bear the quiet burden of their absence, Americans are united in sending one message: We honor your service; we are inspired by your sacrifice; and you have our unyielding support.
To relieve the strain on our forces, my budget increases the number of our soldiers and marines. And to keep our sacred trust with those who serve, we will raise their pay and give our veterans the expanded health care and benefits that they have earned.
To overcome extremism, we must also be vigilant in upholding the values our troops defend, because there is no force in the world more powerful than the example of America. And that is why I have ordered the closing of the detention center at Guantanamo Bay and will seek swift and certain justice for captured terrorists. Because living our values doesn't make us weaker, it makes us safer and it makes us stronger. And that is why I can stand here tonight and say without exception or equivocation that the United States of America does not torture. We can make that commitment here tonight.
In words and deeds, we are showing the world that a new era of engagement has begun. For we know that America cannot meet the threats of this century alone, but the world cannot meet them without America. We cannot shun the negotiating table, nor ignore the foes or forces that could do us harm. We are instead called to move forward with the sense of confidence and candor that serious times demand.
To seek progress towards a secure and lasting peace between Israel and her neighbors, we have appointed an envoy to sustain our effort. To meet the challenges of the 21st century--from terrorism to nuclear proliferation, from pandemic disease to cyber threats to crushing poverty--we will strengthen old alliances, forge new ones, and use all elements of our national power.
And to respond to an economic crisis that is global in scope, we are working with the nations of the G-20 to restore confidence in our financial system, avoid the possibility of escalating protectionism, and spur demand for American goods in markets across the globe. For the world depends on us having a strong economy, just as our economy depends on the strength of the world's.
As we stand at this crossroads of history, the eyes of all people in all nations are once again upon us, watching to see what we do with this moment, waiting for us to lead. Those of us gathered here tonight have been called to govern in extraordinary times. It is a tremendous burden, but also a great privilege, one that has been entrusted to few generations of Americans. For in our hands lies the ability to shape our world for good or for ill.
I know that it's easy to lose sight of this truth, to become cynical and doubtful, consumed with the petty and the trivial. But in my life, I have also learned that hope is found in unlikely places, that inspiration often comes not from those with the most power or celebrity, but from the dreams and aspirations of ordinary Americans who are anything but ordinary.
I think of Leonard Abess, a bank president from Miami who reportedly cashed out of his company, took a $60 million bonus, and gave it out to all 399 people who worked for him, plus another 72 who used to work for him. He didn't tell anyone, but when the local newspaper found out, he simply said, "I knew some of these people since I was 7 years old. It didn't feel right getting the money myself."
I think about Greensburg, Kansas, a town that was completely destroyed by a tornado, but is being rebuilt by its residents as a global example of how clean energy can power an entire community, how it can bring jobs and businesses to a place where piles of bricks and rubble once lay. "The tragedy was terrible," said one of the men who helped them rebuild. "But the folks here know that it also provided an incredible opportunity."
I think about Ty'Sheoma Bethea, the young girl from that school I visited in Dillon, South Carolina, a place where the ceilings leak, the paint peels off the walls, and they have to stop teaching six times a day because the train barrels by their classroom. She had been told that her school is hopeless, but the other day after class she went to the public library and typed up a letter to the people sitting in this Chamber. She even asked her principal for the money to buy a stamp. The letter asks us for help and says: "We are just students trying to become lawyers, doctors, Congressmen like yourself, and one day President, so we can make a change to not just the State of South Carolina, but also the world. We are not quitters." That's what she said: "We are not quitters."
These words and these stories tell us something about the spirit of the people who sent us here. They tell us that even in the most trying times, amid the most difficult circumstances, there is a generosity, a resilience, a decency, and a determination that perseveres, a willingness to take responsibility for our future and for posterity. Their resolve must be our inspiration. Their concerns must be our cause. And we must show them and all our people that we are equal to the task before us.
I know--look, I know that we haven't agreed on every issue thus far. [Laughter] There are surely times in the future where we will part ways. But I also know that every American who is sitting here tonight loves this country and wants it to succeed. I know that. That must be the starting point for every debate we have in the coming months and where we return after those debates are done. That is the foundation on which the American people expect us to build common ground.
And if we do, if we come together and lift this Nation from the depths of this crisis, if we put our people back to work and restart the engine of our prosperity, if we confront without fear the challenges of our time and summon that enduring spirit of an America that does not quit, then someday years from now our children can tell their children that this was the time when we performed, in the words that are carved into this very Chamber, "something worthy to be remembered."
Thank you. God bless you, and may God bless the United States of America. Thank you.
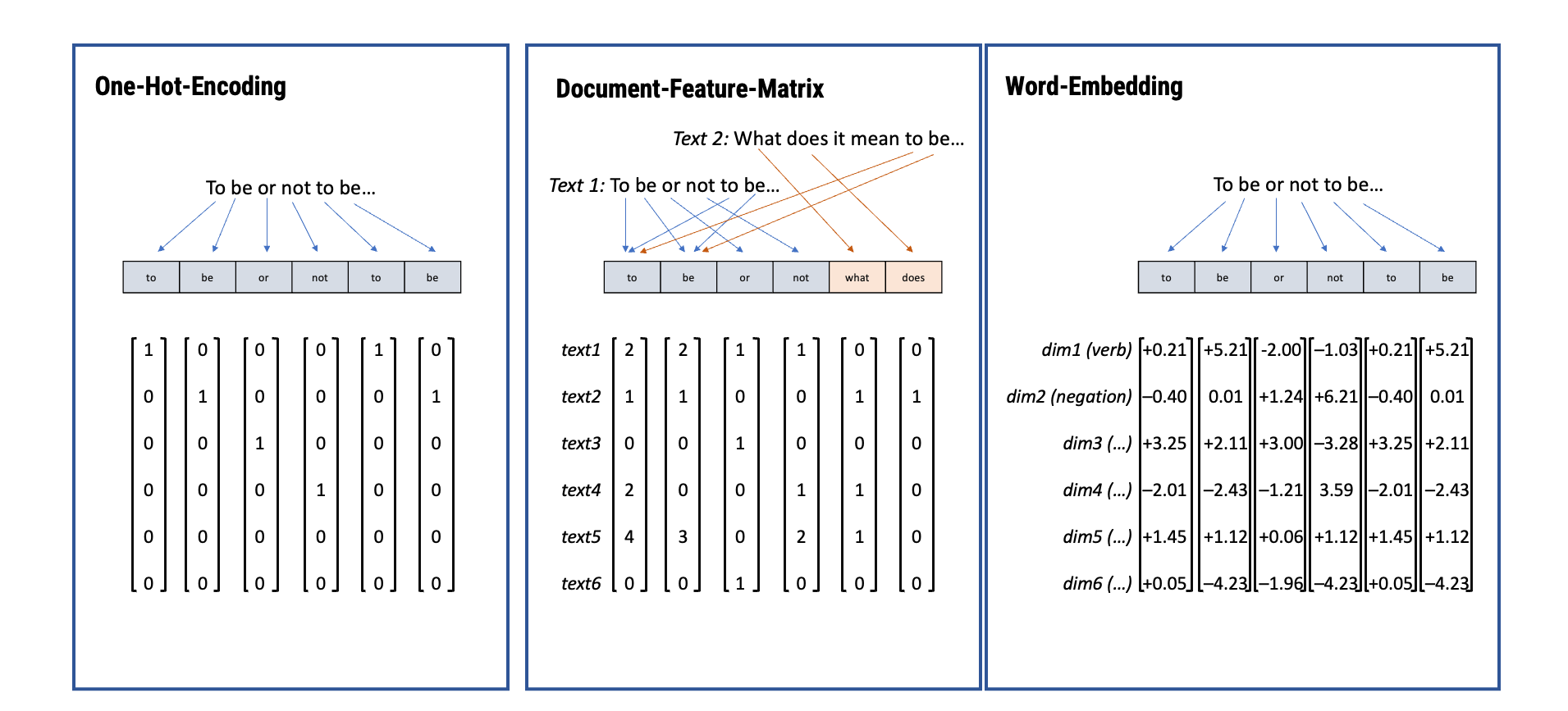
“Bag-of-Words” Approach
Both representations follow the so-called “bag-of-word” model
Such a model disregards grammar and word order and only focus on word frequencies
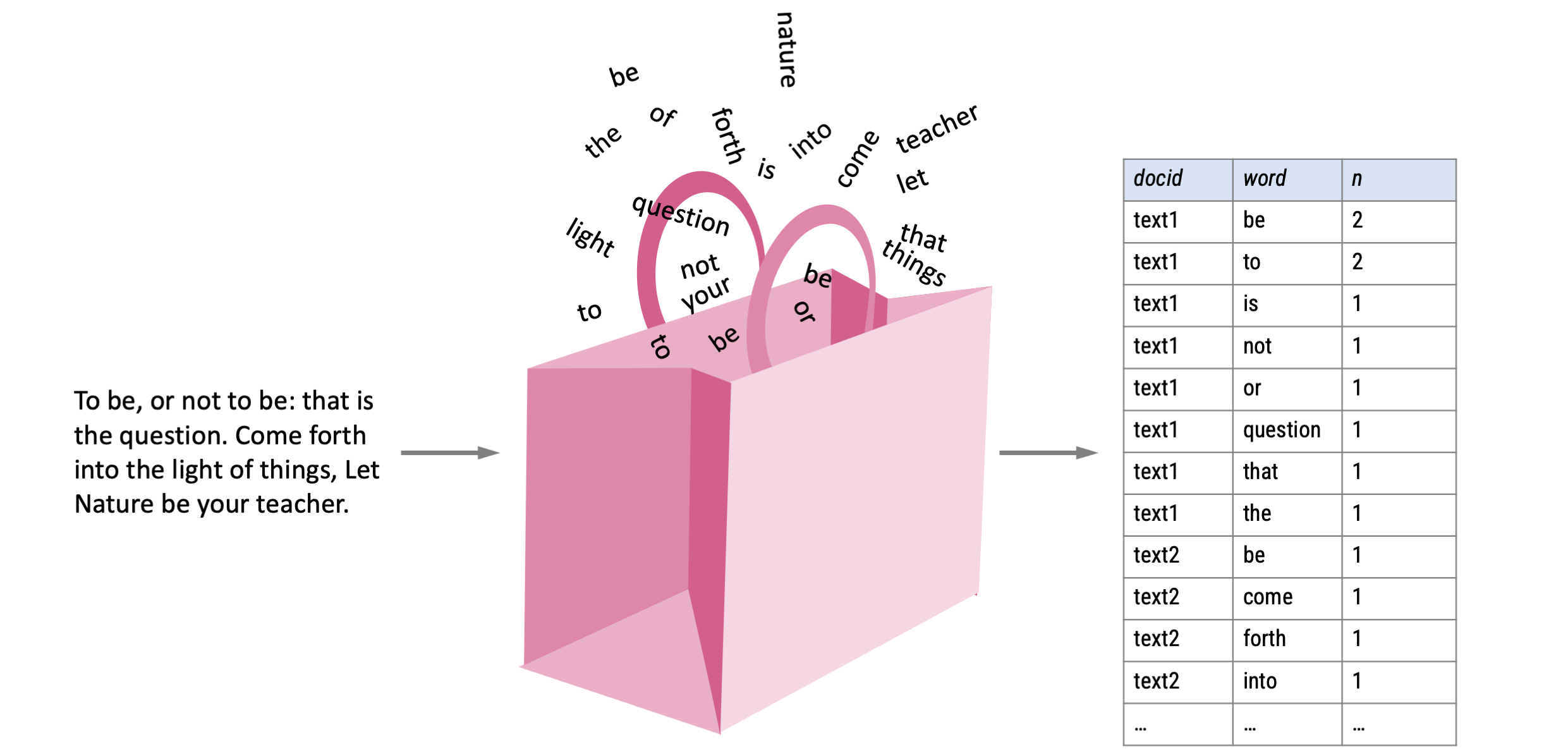
The (un-)avoidable wordcloud
One of the most famous text visualizations is the word cloud, an image where each word is displayed in a size that is representative of its frequency.
Word clouds are often criticized since they are (sometimes) pretty but mostly not very informative.
Only a single aspect of the words is visualized (frequency), which is often not that informative: the most frequent words are generally uninformative “stop words” like “the” and “I”.

Alternative (better?) visualization
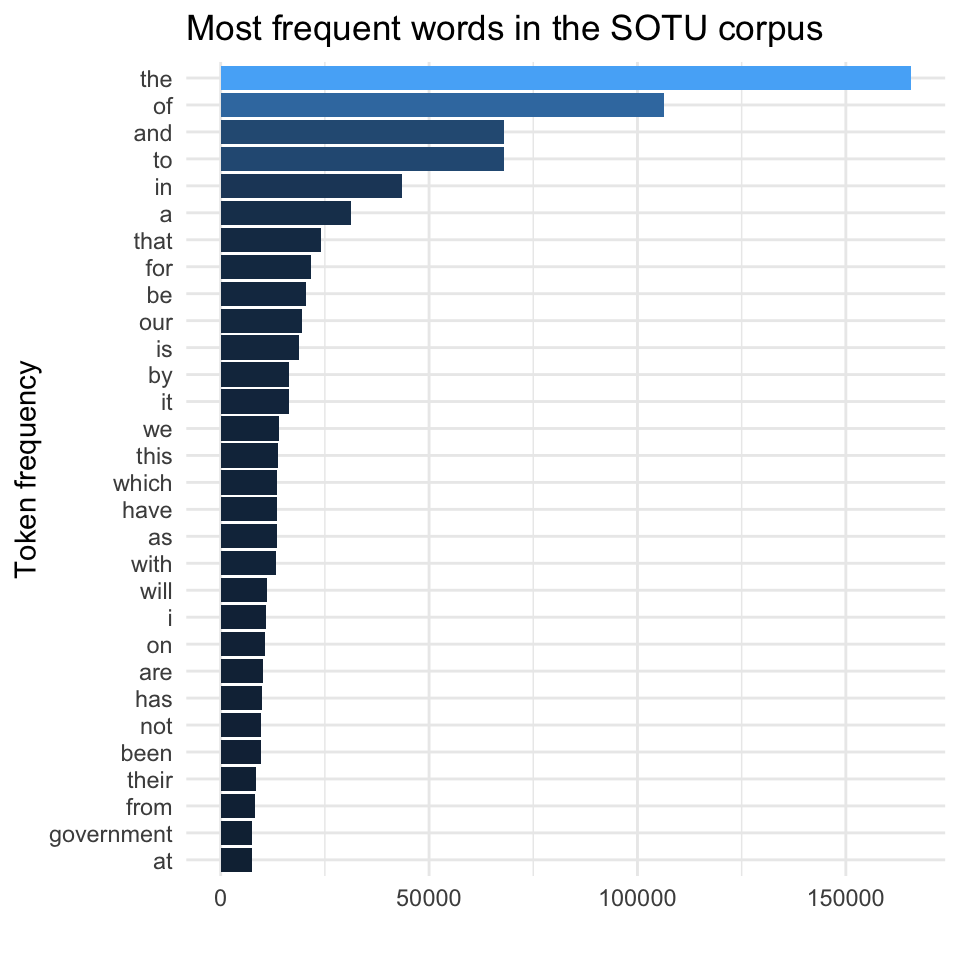
The effect of such text cleaning

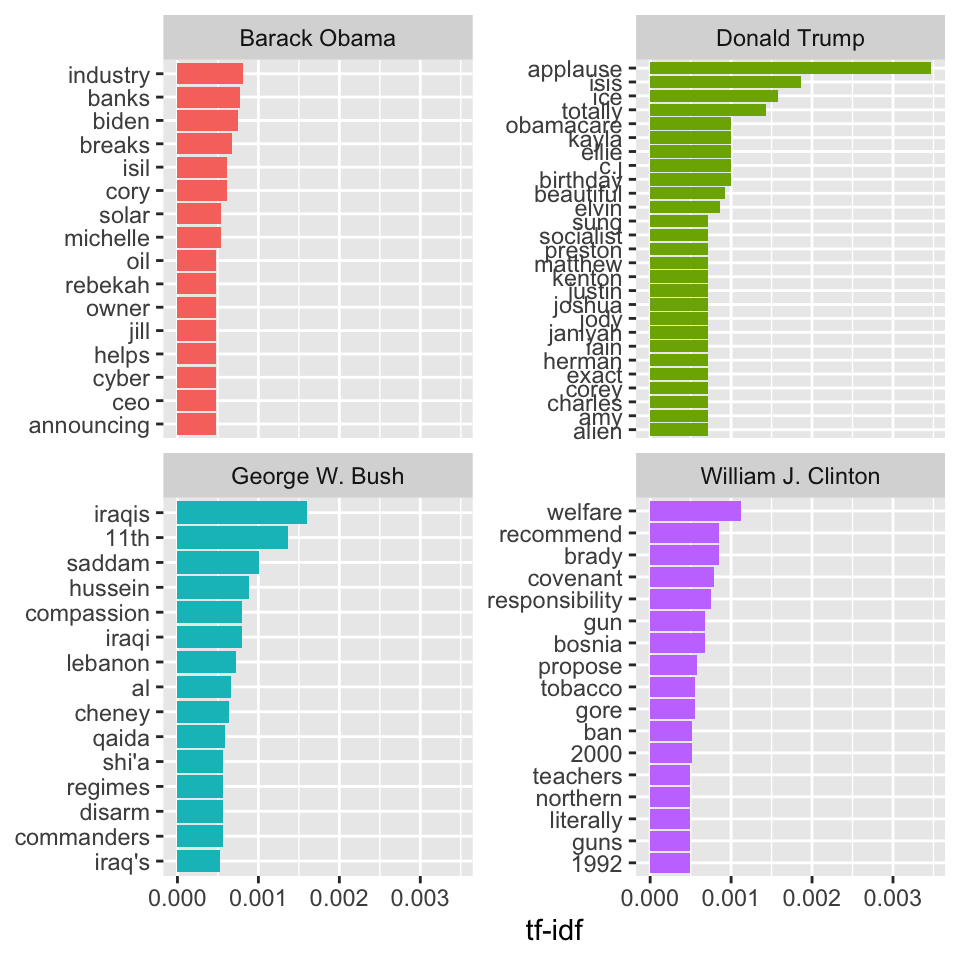
Most “important” words in presidents’ speeches
The statistic tf-idf is intended to measure how important a word is to a document in a collection of documents, for example, to one president in a collection of speeches:
What are deductive approaches?
Quite old technique of content analysis (since 60s)
Coding rules are set a priori by researcher based on a predefined “text theory”
Computer then uses these rules to decode text in a deterministic way
Rules can differ substantially:
- based on individual words or group of words (e.g., articles that contain “government” are coded as “politics”)
- based on patterns (e.g., the sender of a mail can be identified by looking for “FROM:”)
- combinations of both
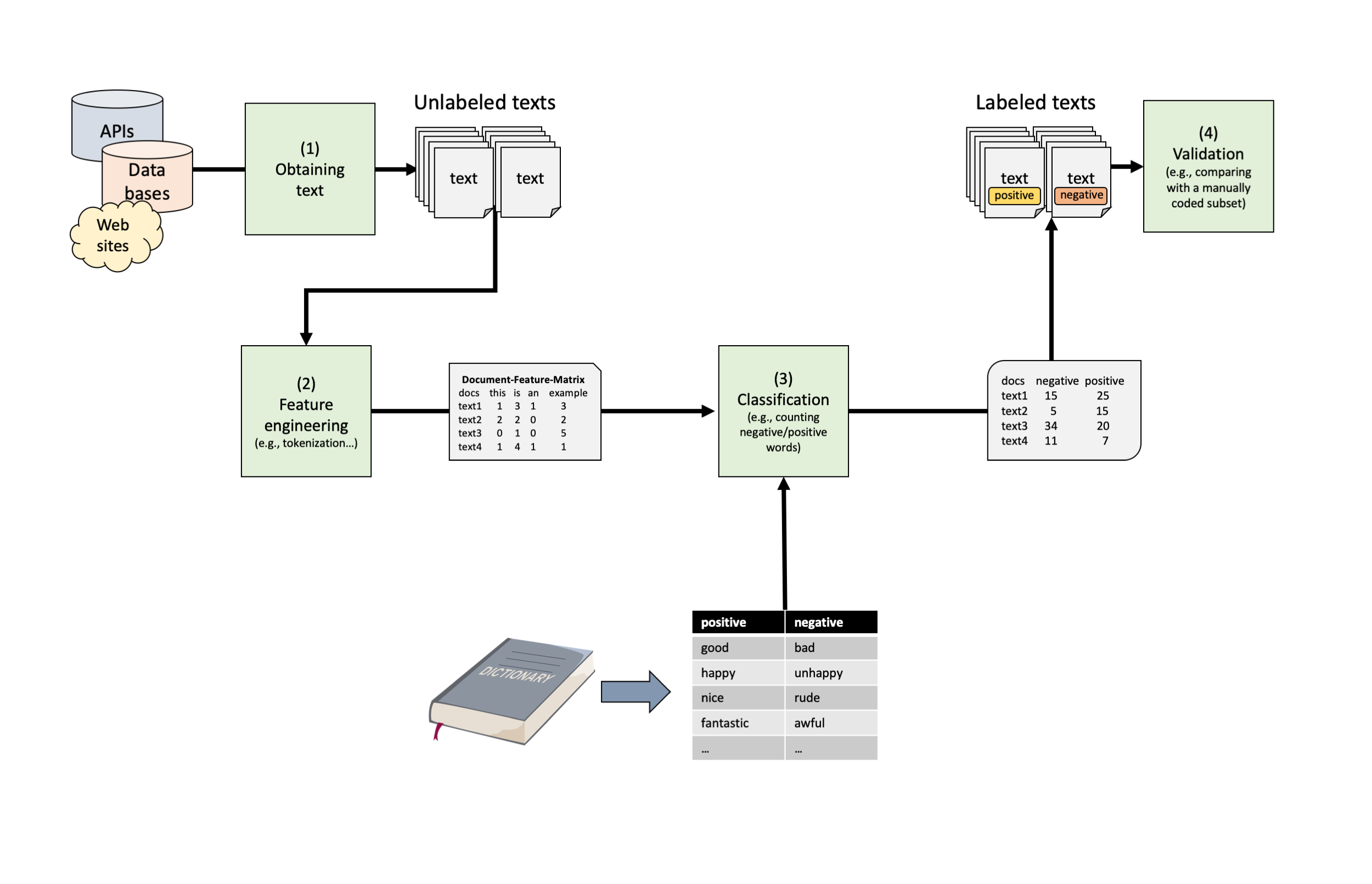
Text Classification Pipeline Using Dictionaries
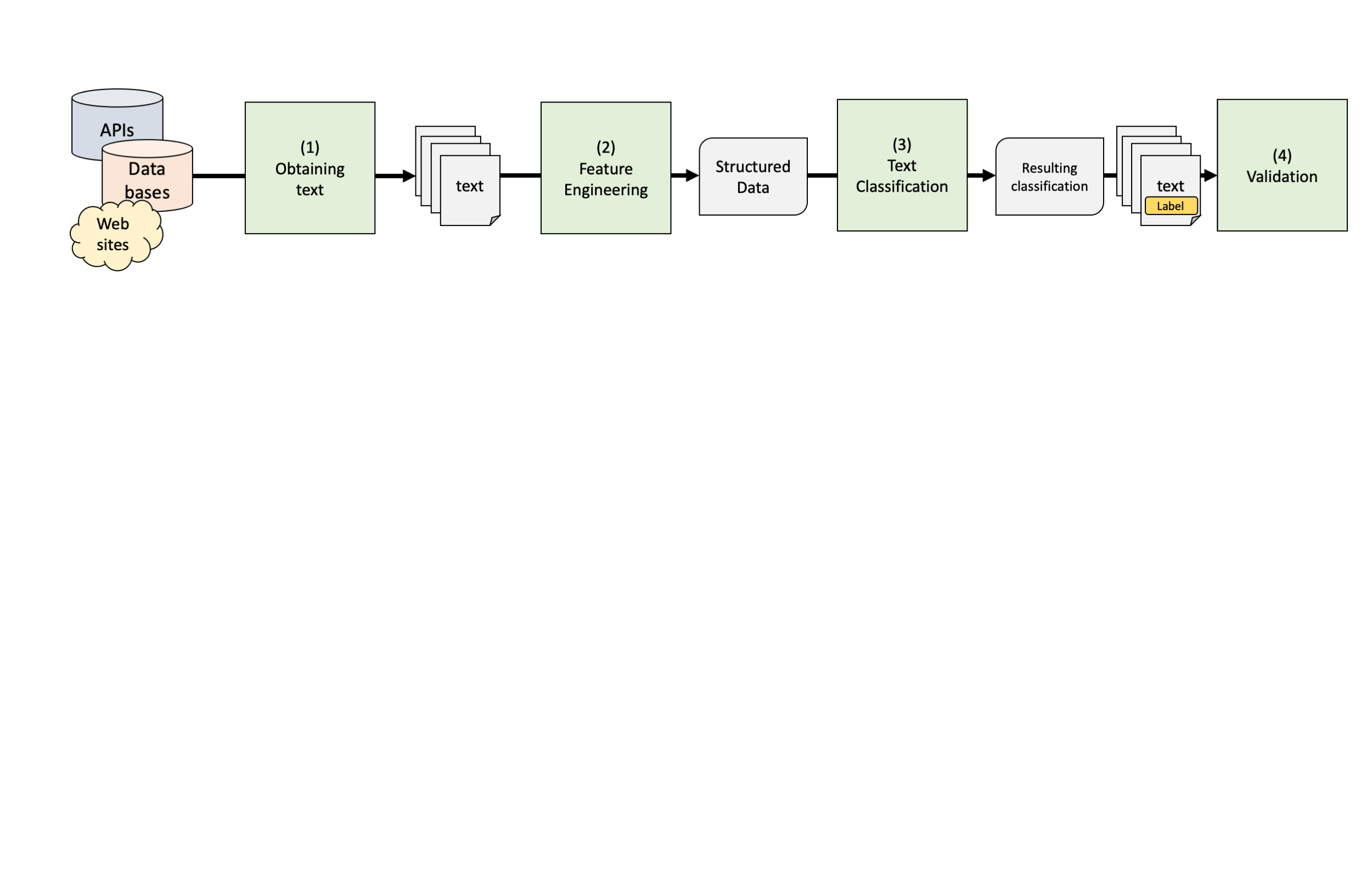
Text Classification Pipeline Using Dictionaries
Emotionality per speech
- For example, we can compute the amount of words coded with a particular emotions per speech
library(ggridges)
# Summarize data
sotu_plot_data <- sotu_emotions2 |>
group_by(docid, sentiment) |>
summarize(n = n()) |>
mutate(prop = n/sum(n)) |>
filter(!is.na(sentiment))
# Plotting the data
ggplot() +
geom_line(data = sotu_plot_data,
aes(x = sentiment, y = prop*100,
group = docid),
linewidth = .5,
alpha = .05, color = "grey50")+
geom_line(data = sotu_plot_data |> filter(docid == 1),
aes(x = sentiment, y = prop*100, group = 1),
linewidth = 2,
color = "steelblue",
alpha = .6) +
annotate("text", x = "fear", y = 8.5, size = 4.5,
label = "First speech by Washington",
color = "steelblue", ) +
theme_ridges(font_size = 16) +
coord_flip() +
labs(x = "", y = "Proportion of words in speech",
title = "Emotionality in SOTU speeches")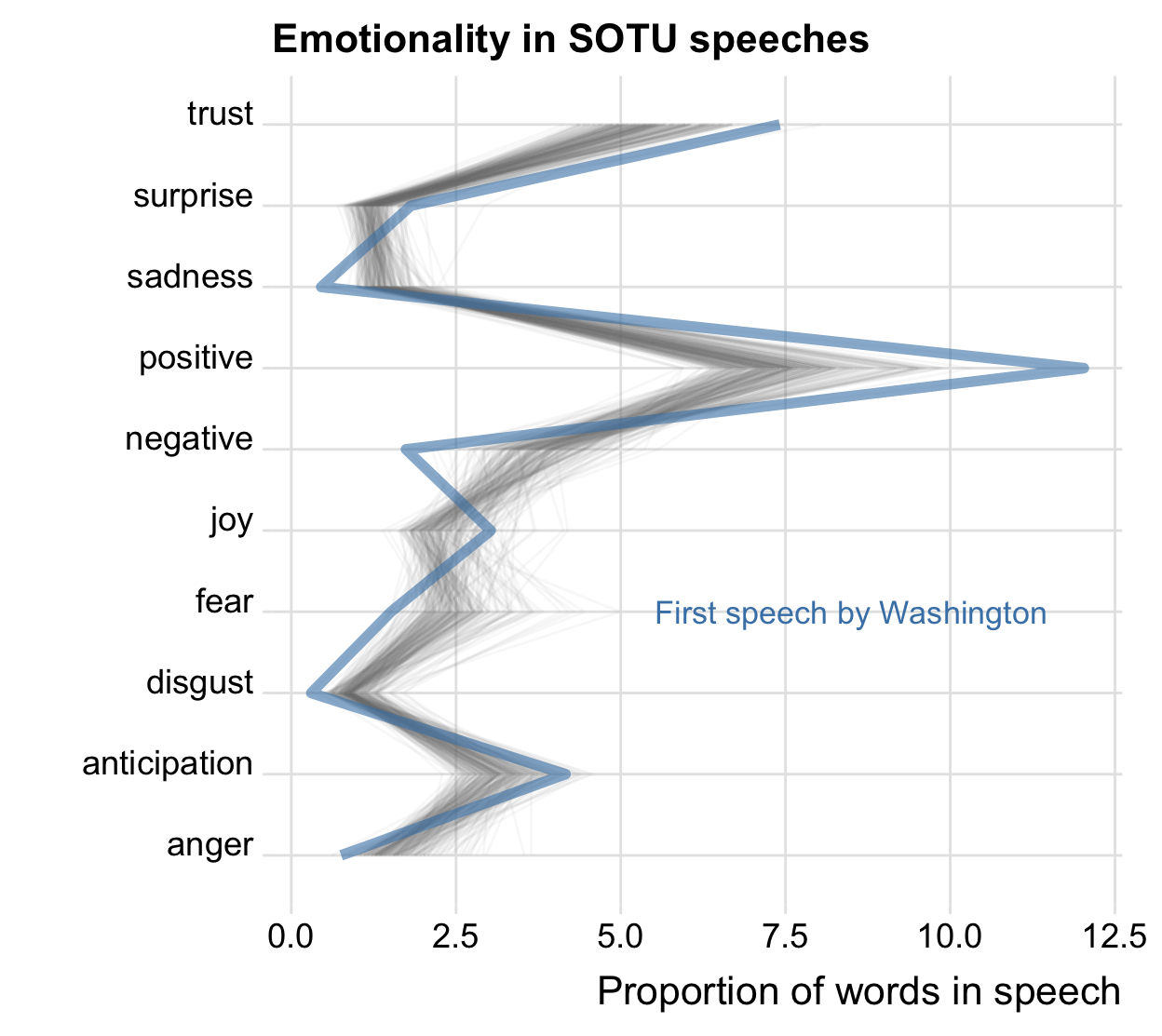
Emotions over the years
# Summarize data
sotu_emo_time <- sotu_emotions2 |>
group_by(year, sentiment) |>
summarize(n = n()) |>
mutate(prop = n / sum(n)) |>
ungroup() |>
filter(!is.na(sentiment))
# Plot the summarized data
ggplot(sotu_emo_time) +
geom_ridgeline(aes(x=year, y=sentiment,
height=prop/max(prop),
fill=sentiment)) +
theme_ridges() +
guides(fill="none") +
labs(title = "Emotionality over the years")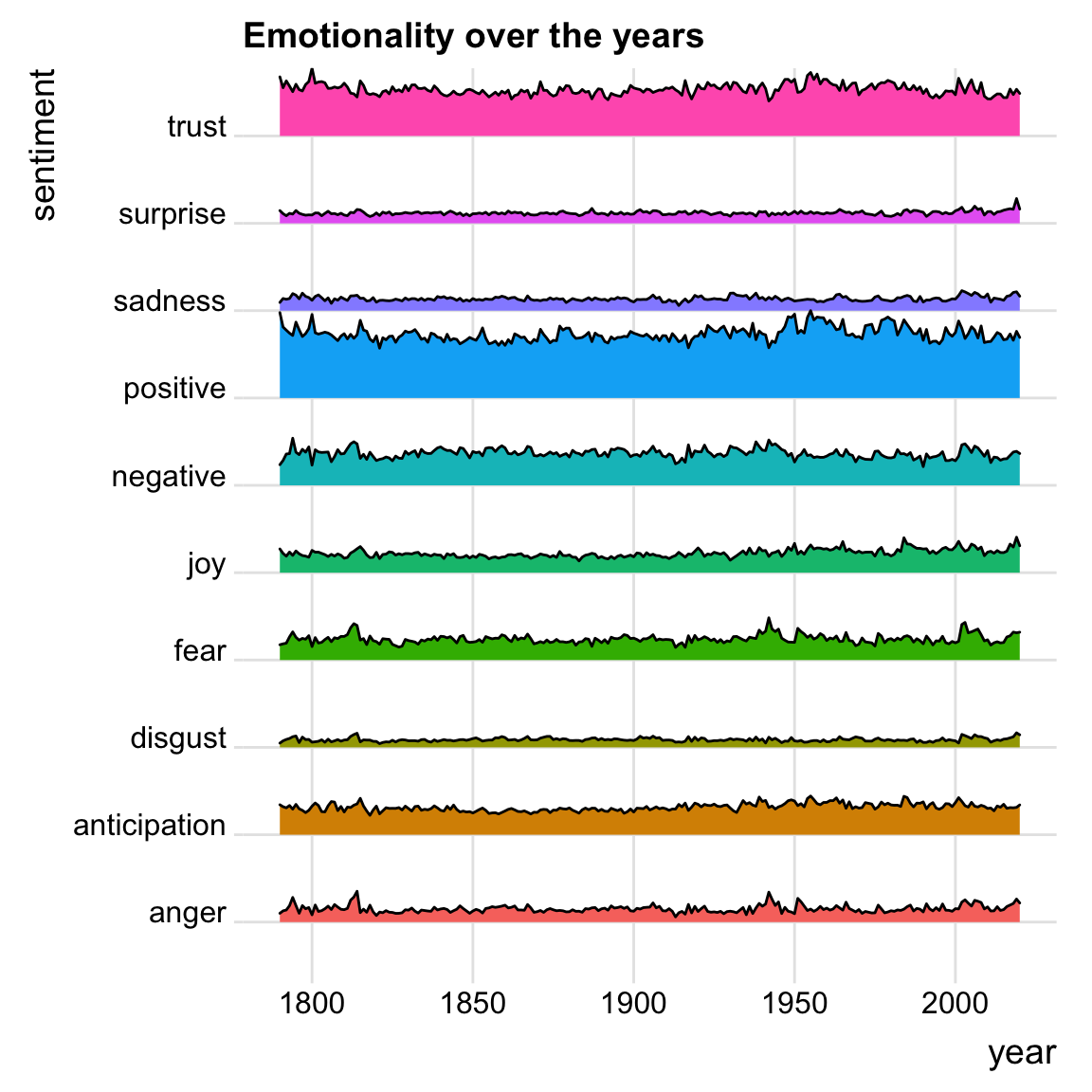
Validation procedure
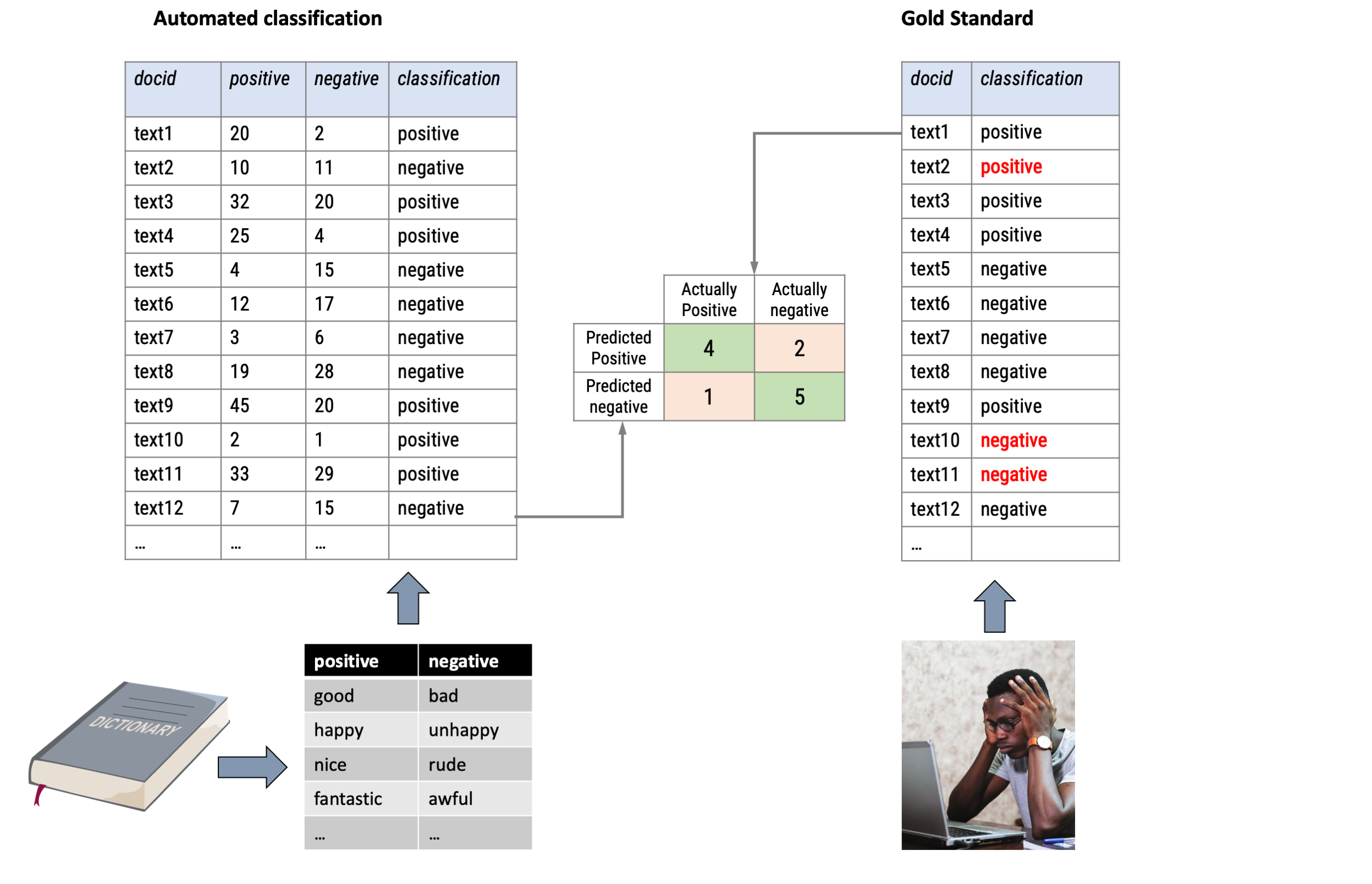
Confusion Matrix
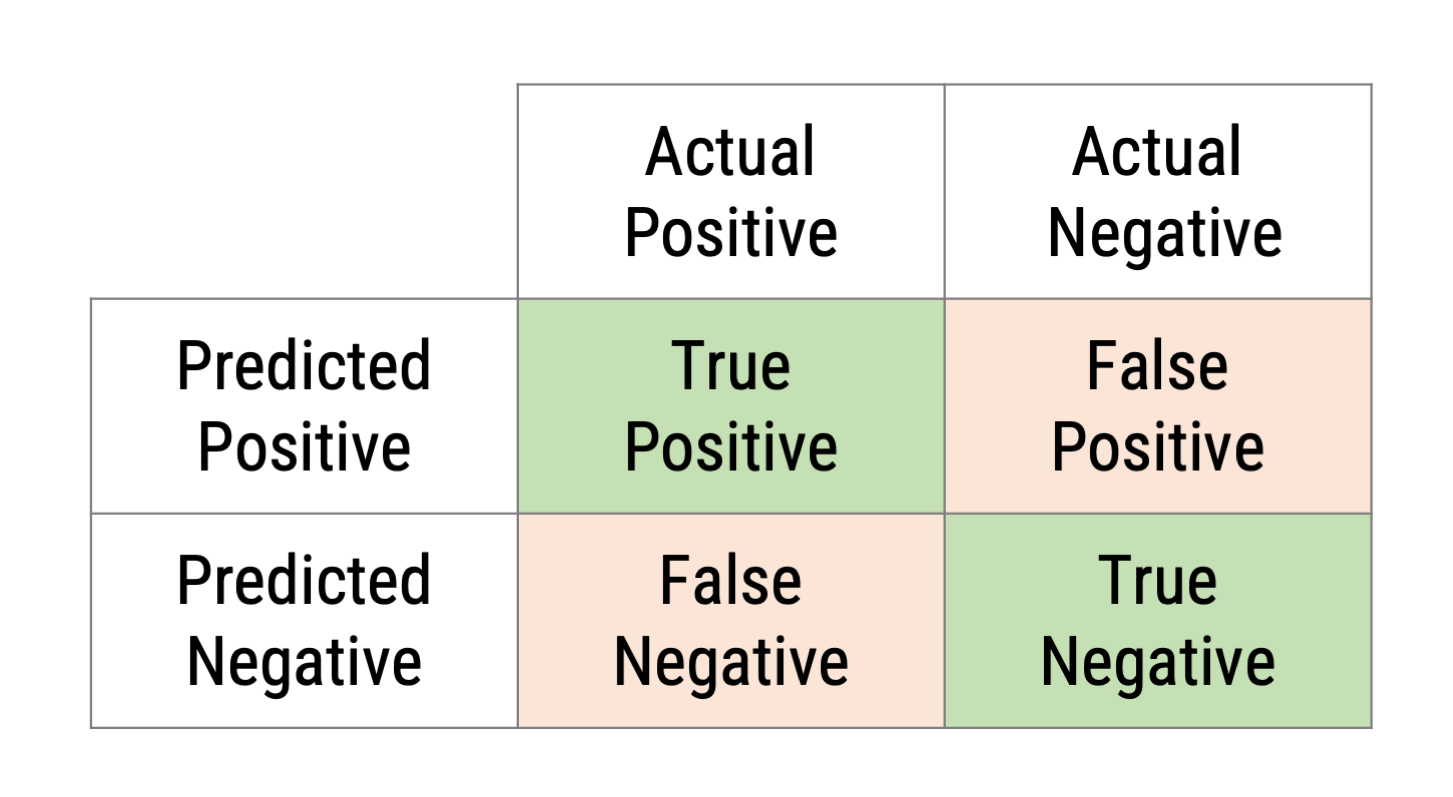
Basis for all validity/performance scores is always the confusion matrix between algorithm and manual coder that assessed the same content
Disadvantages
- No correction of random chance agreements
- only nominal scales
- no accounting for missings
Alternative: Cronbach’s Alpha (but often seen as too strict)
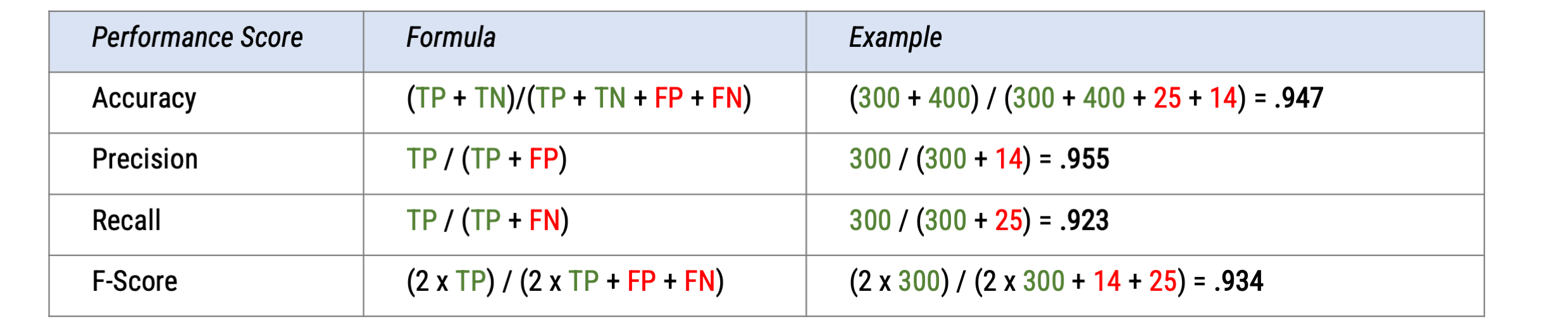
Performance scores
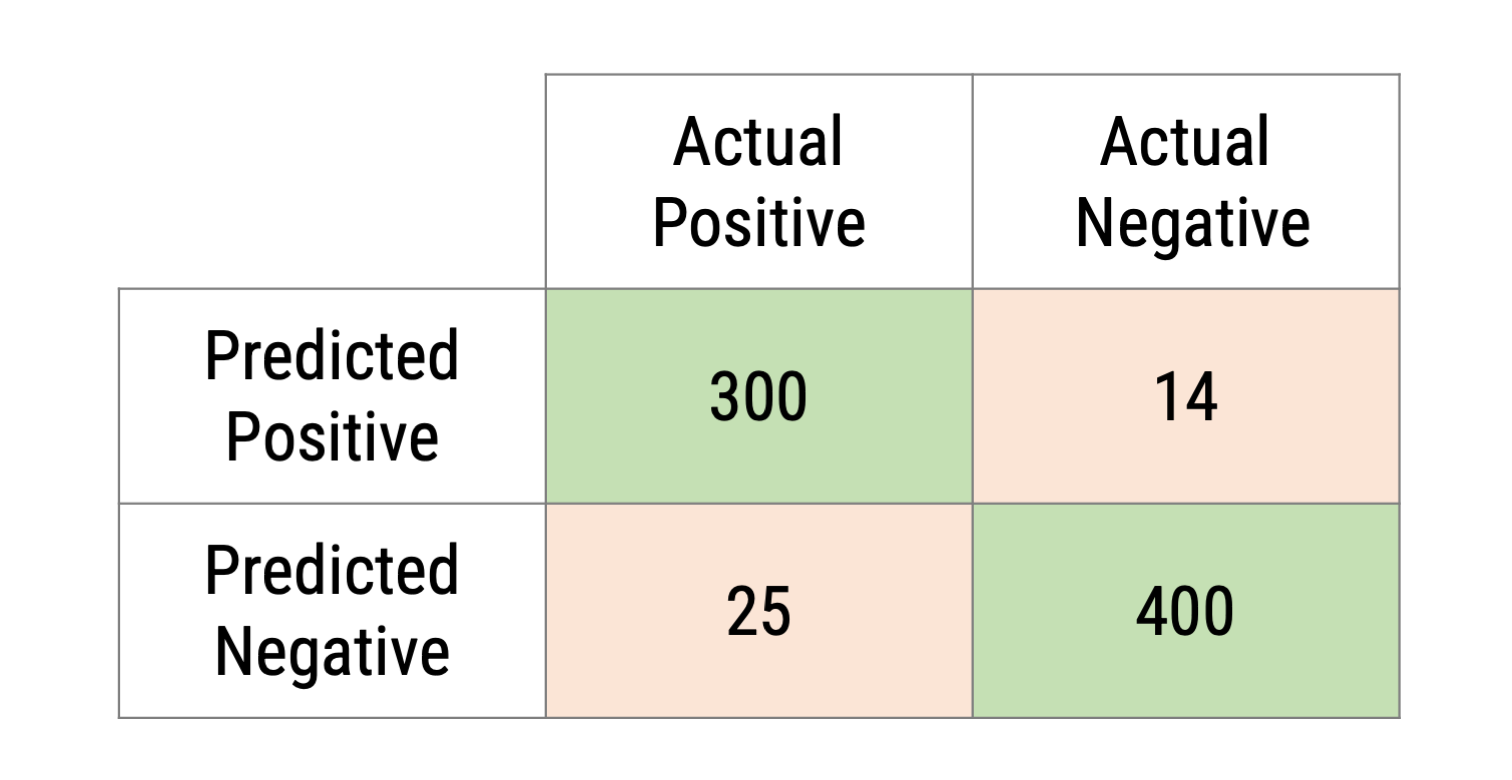
No clear thresholds: need to be assessed in the research context, but values closer to 1 are desirable
Can be used to compare the performance of different approaches!
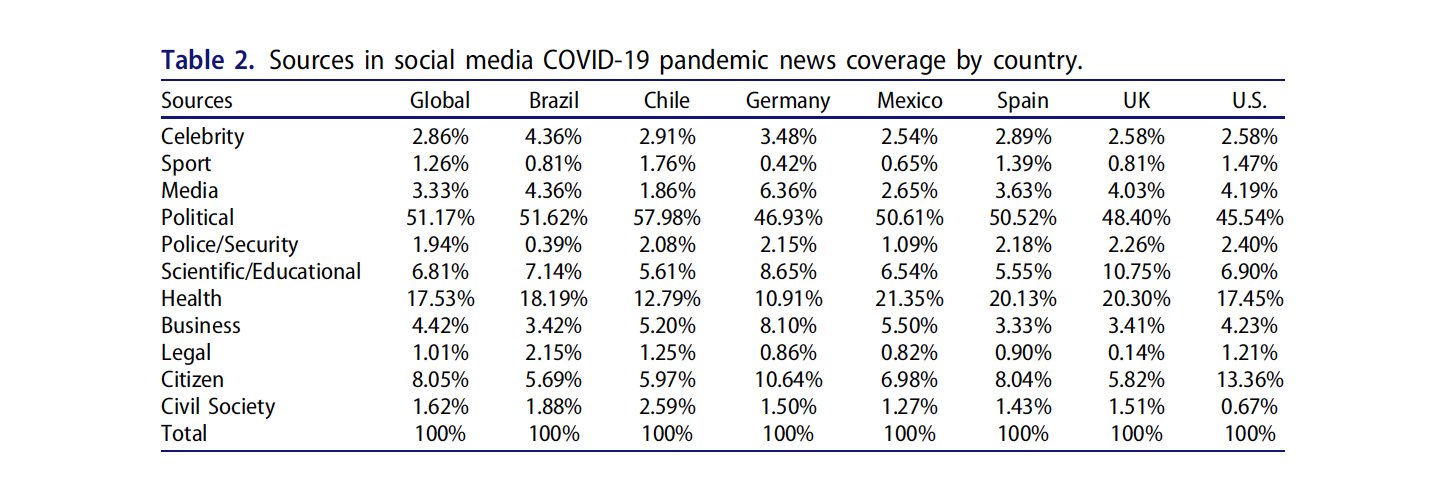
Example 1: Sourcing Pandemic News (Mellado et al)
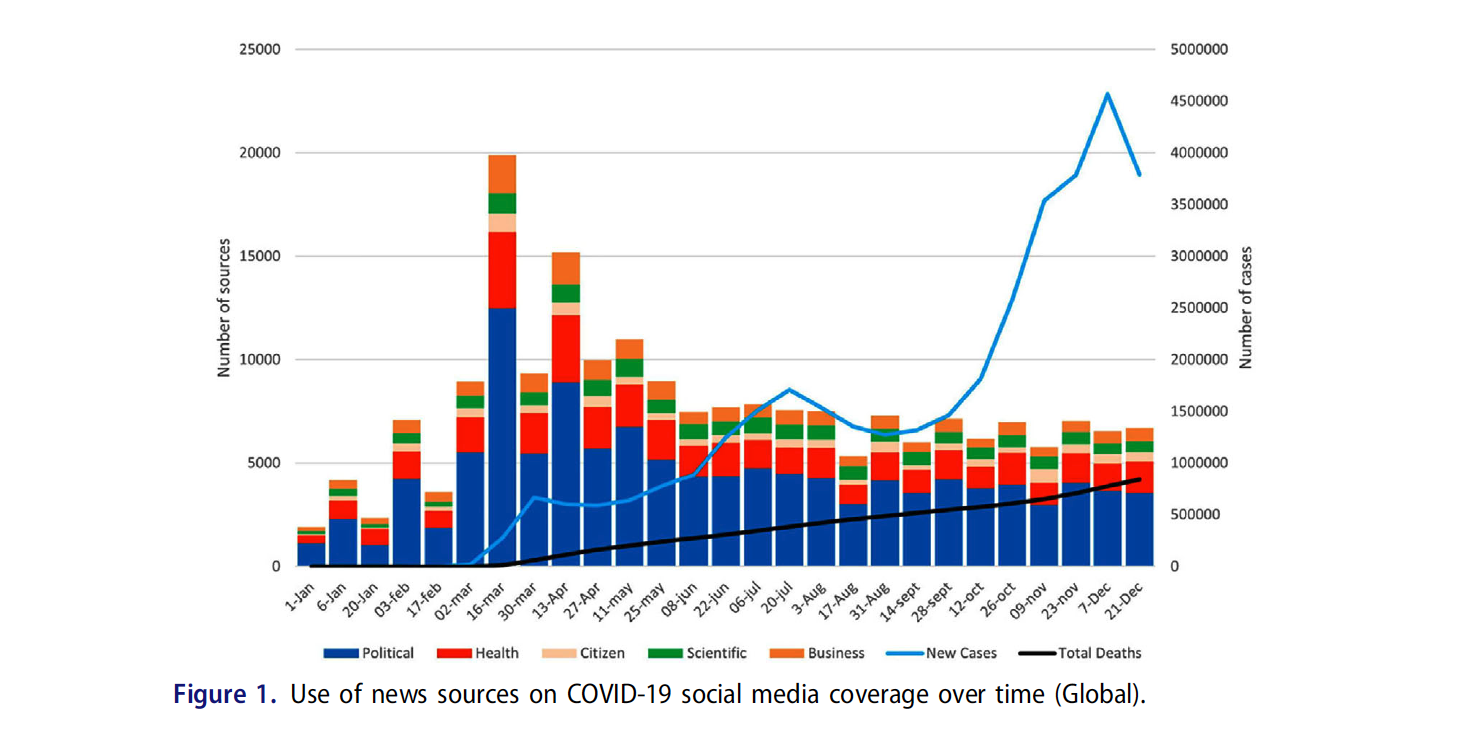
The study analyzes the sources and actors present in more than 940,000 posts on COVID-19 published in the 227 Facebook, Instagram, and Twitter accounts of 78 sampled news outlets between January 1 and December 31 of 2020
The analysis shows the dominance of political sources across countries and platforms, particularly in Latin America
It demonstrates the strong role of the state in constructing pandemic news and suggesting that mainstream news organizations’ social media posts maintain a strong elite orientation
Health sources were also prominent, while significant diversity of sources, including citizen sources, emerged as the pandemic went on

Mellado et al., 2021
Example 1: Results - Source distribution per country
Example 1: Results - Source distribution over time
Example 2: Political migration on social media
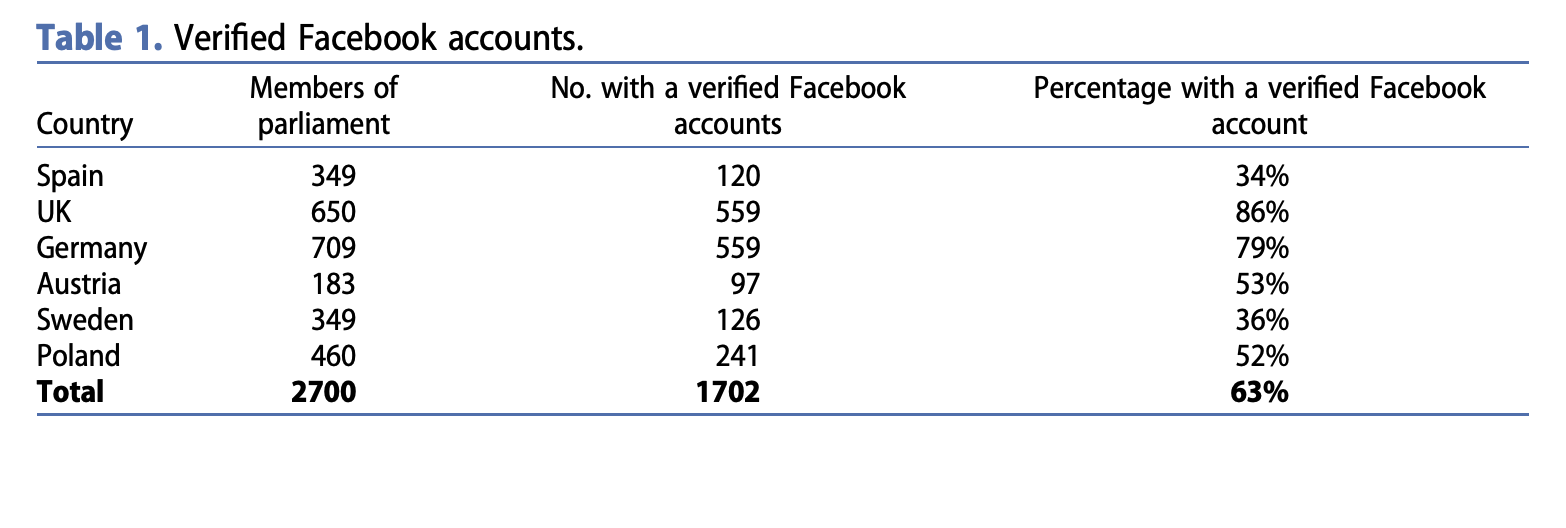
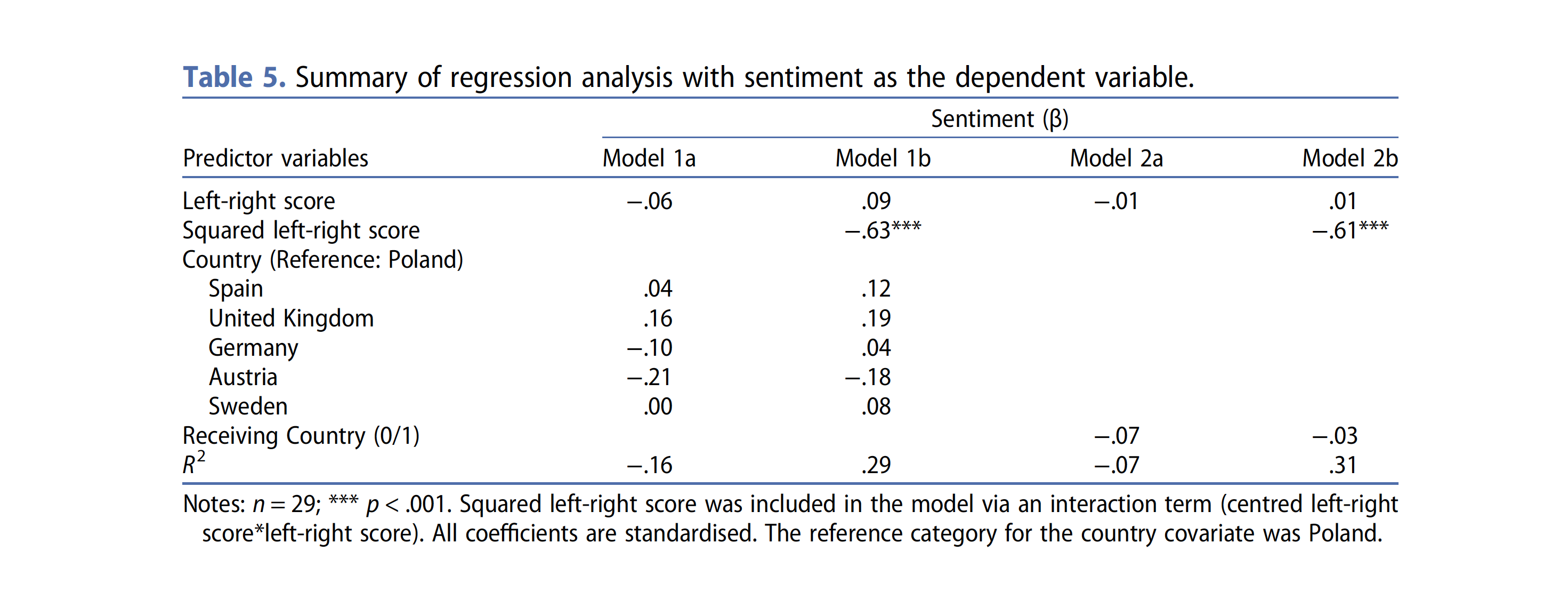
Heidenreich and colleagues (2019), analyzed migration discourses in the Facebook accounts of political actors (n=1702) across six European countries (Spain, UK, Germany, Austria, Sweden and Poland)
present new insights into the visibility of migration as a topic
investigated sentiment about migration, revealing country- and party-specific patterns

Heidenreich et al., 2019
Example 2: Methods
Downloaded textual data for all migration-related posts (n = 24,578) of members of parliaments (n = 1702) in six countries
Used automated contend analysis to estimate sentiment towards migration in each post
Machine translated the whole corpus into English
Used a dictionary-approach (Lexicoder; Young and Soroka, 2012) to cound positive and negative words
Computed sentiment for each document by calculating as the sum of the scores for all words bearing positive sentiment minus the sum of all scores from negative words, divided by the number of words.
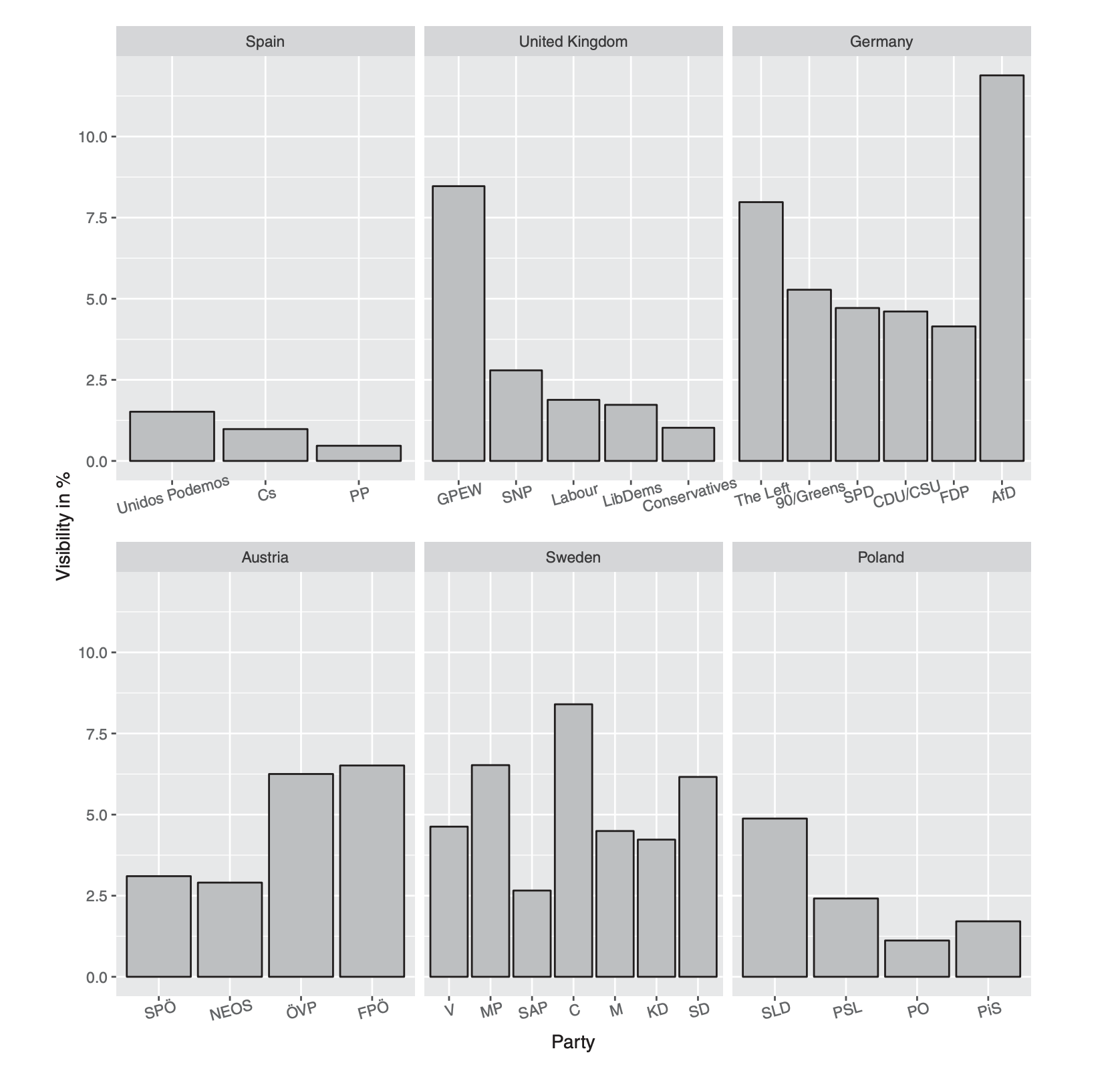
Example 2: Results - Visibility
In Germany and Austria there is indeed descriptive evidence that parties of the right discuss migration more frequently in their Facebook status posts than other parties
Conversely, in Spain, the UK and Poland the topic tended to be more prominent in the posts of left-wing parties
At first glance, Sweden seems to be an outlier.
In sum there is no consistent overall pattern supporting the hypothesis that right wing parties pay more attention to the topic of migration on Facebook than left leaning parties
Example 2: Results - Sentiment
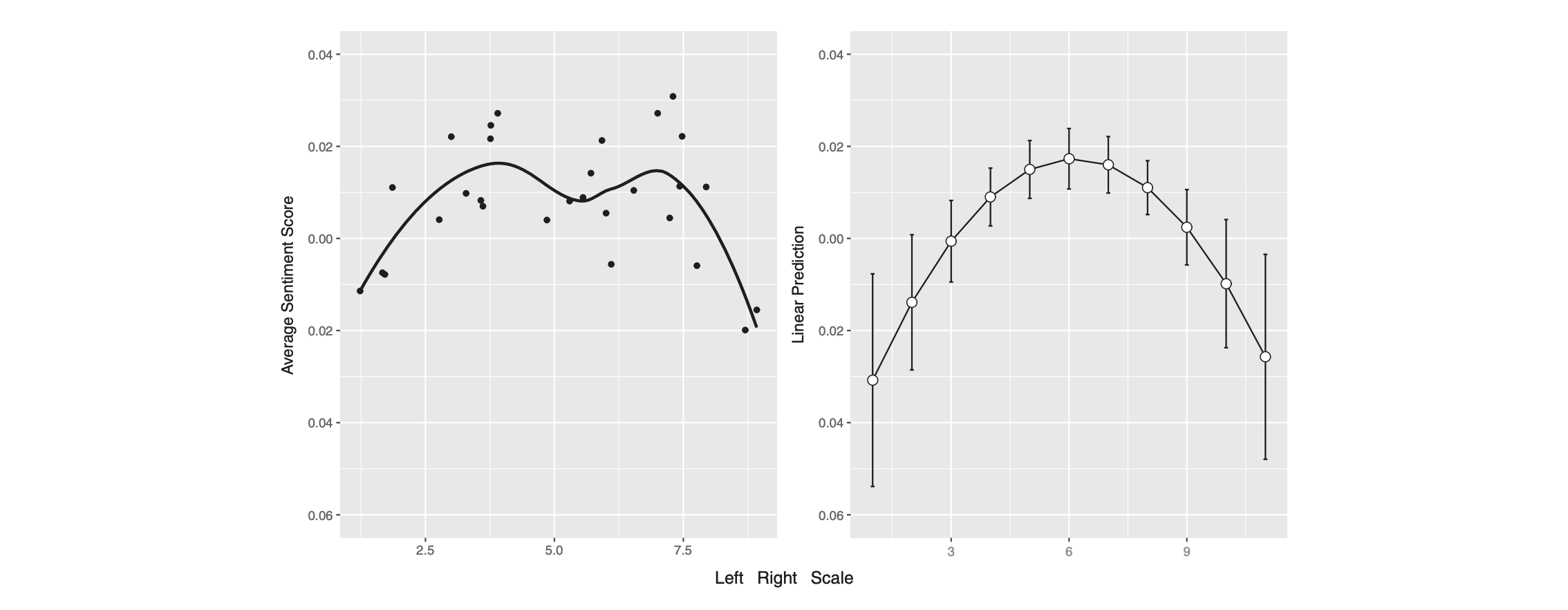
Example 2: Results - Predicting sentiment
Overview
Next week
Introduction to supervised machine learning
Using neural networks for text classification
The idea of deep learning
Better word representations using word-embeddings

Thank you for your attention!
![]()