

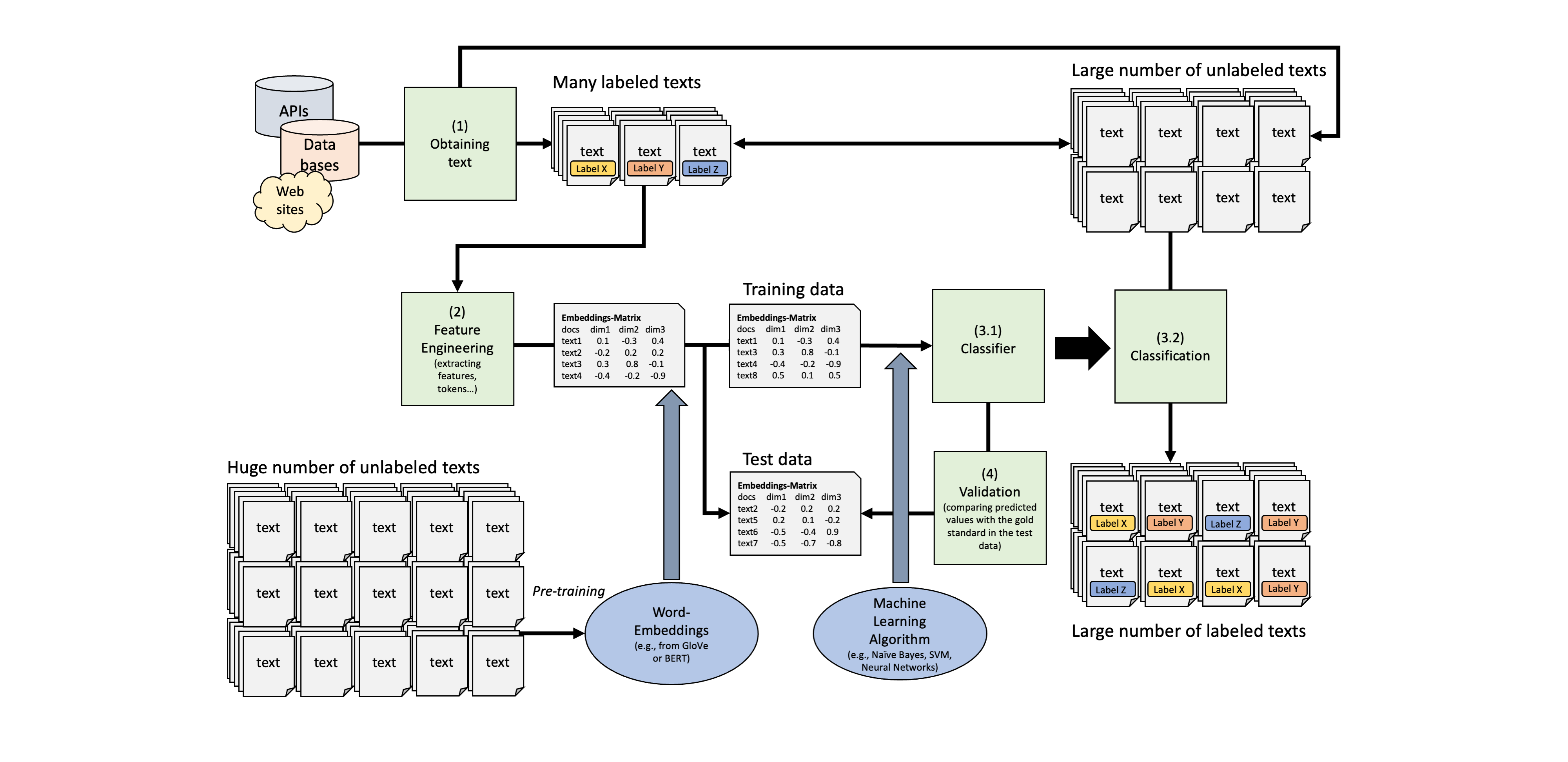
Main results
Week 3: Neural Networks and Word-Embeddings
Machine learning is the study of computer algorithms that can improve automatically through experience and by the use of data
Due to the “black box” nature of the algorithm’s operations, it is often seen as a form of artificial intelligence
Source: qlik
 Successful machine learning in practical contexts:
Successful machine learning in practical contexts:
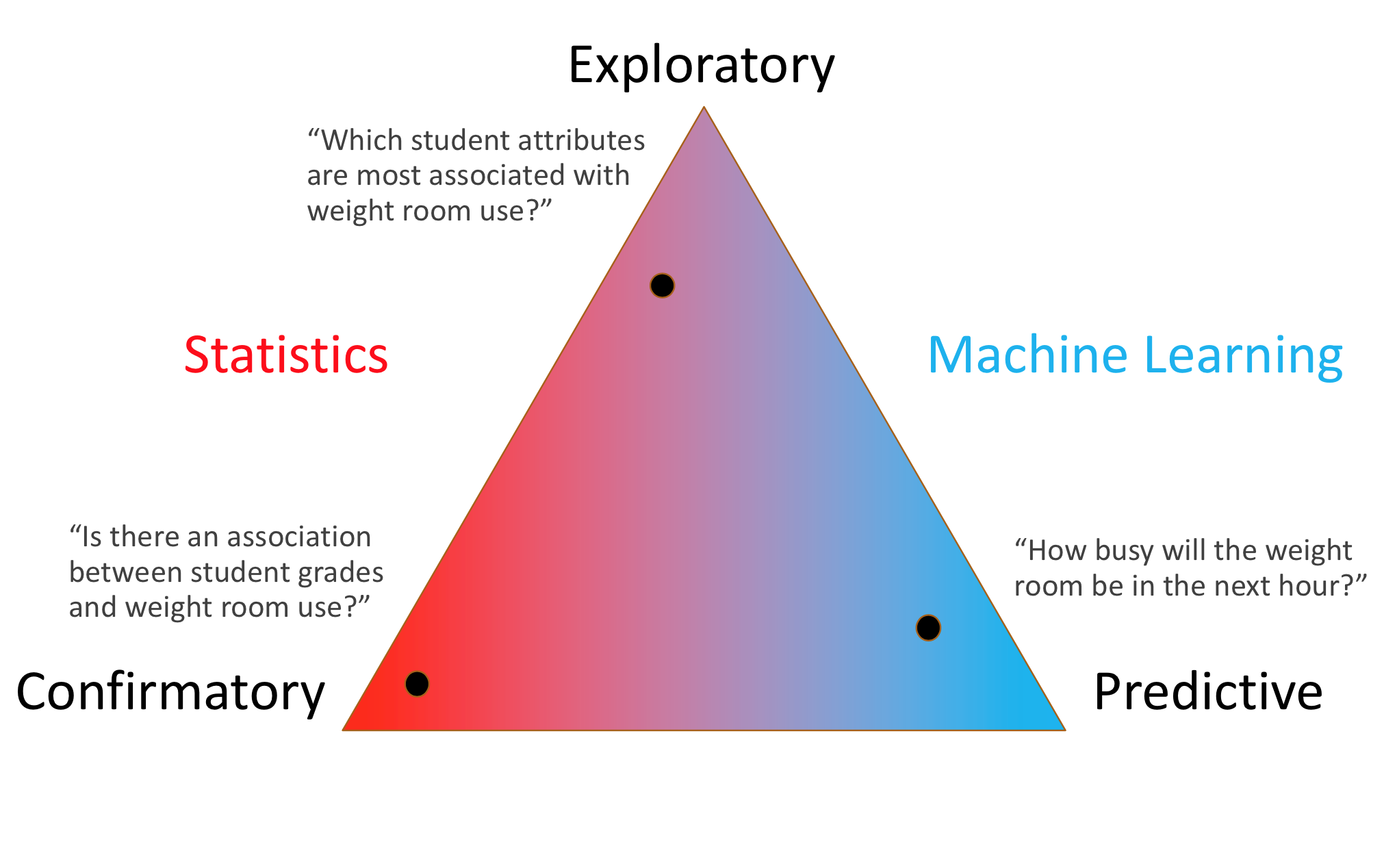
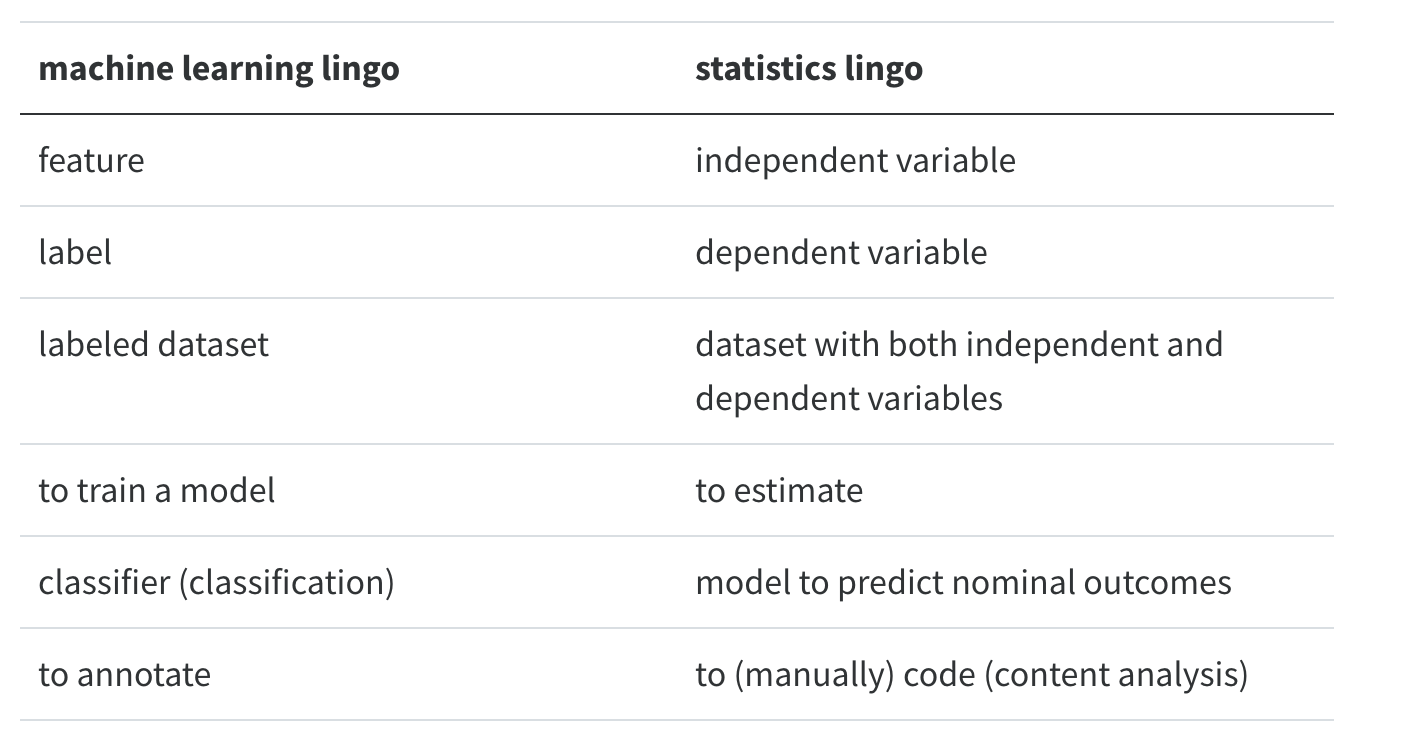
Machine learning, many people joke, is nothing but a fancy name for statistics.
There is some truth to this: the term “logistic regression” will sound familiar to both statisticians and machine learning practitioners.
Still, there are some differences between traditional statistical approaches and the machine learning approach, even if some of the same mathematical tools are used.
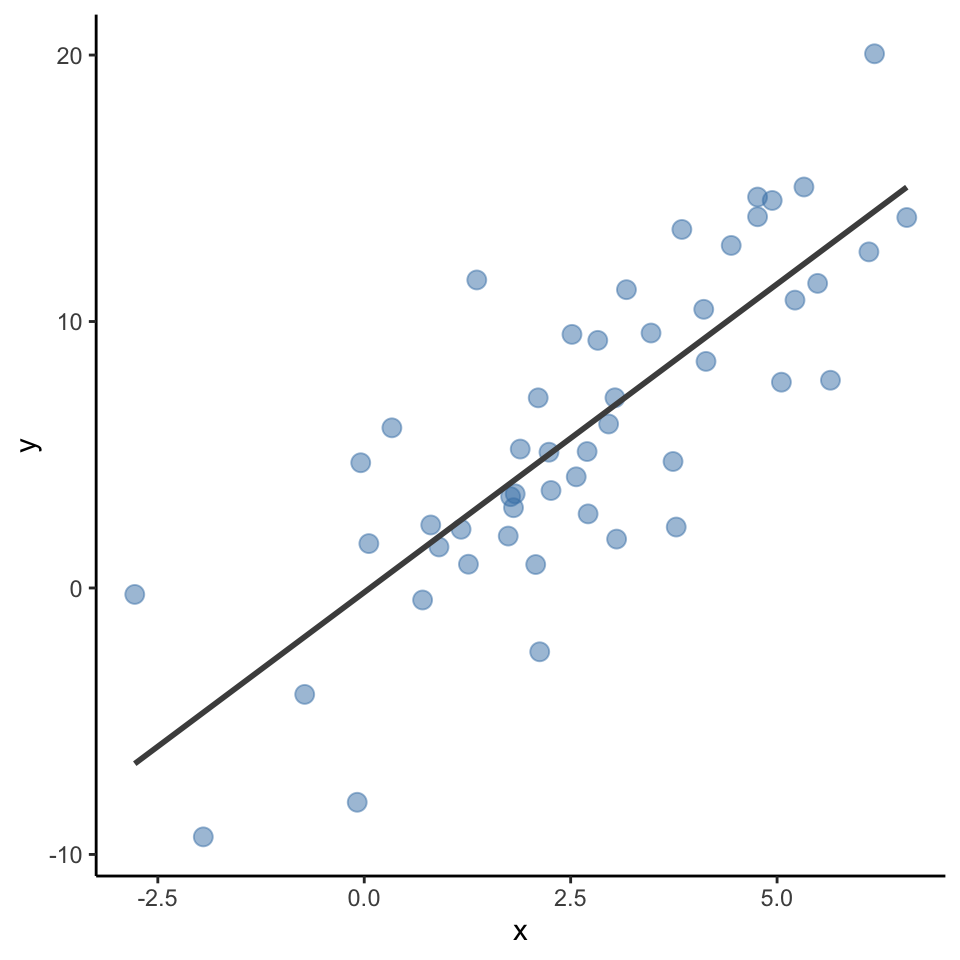
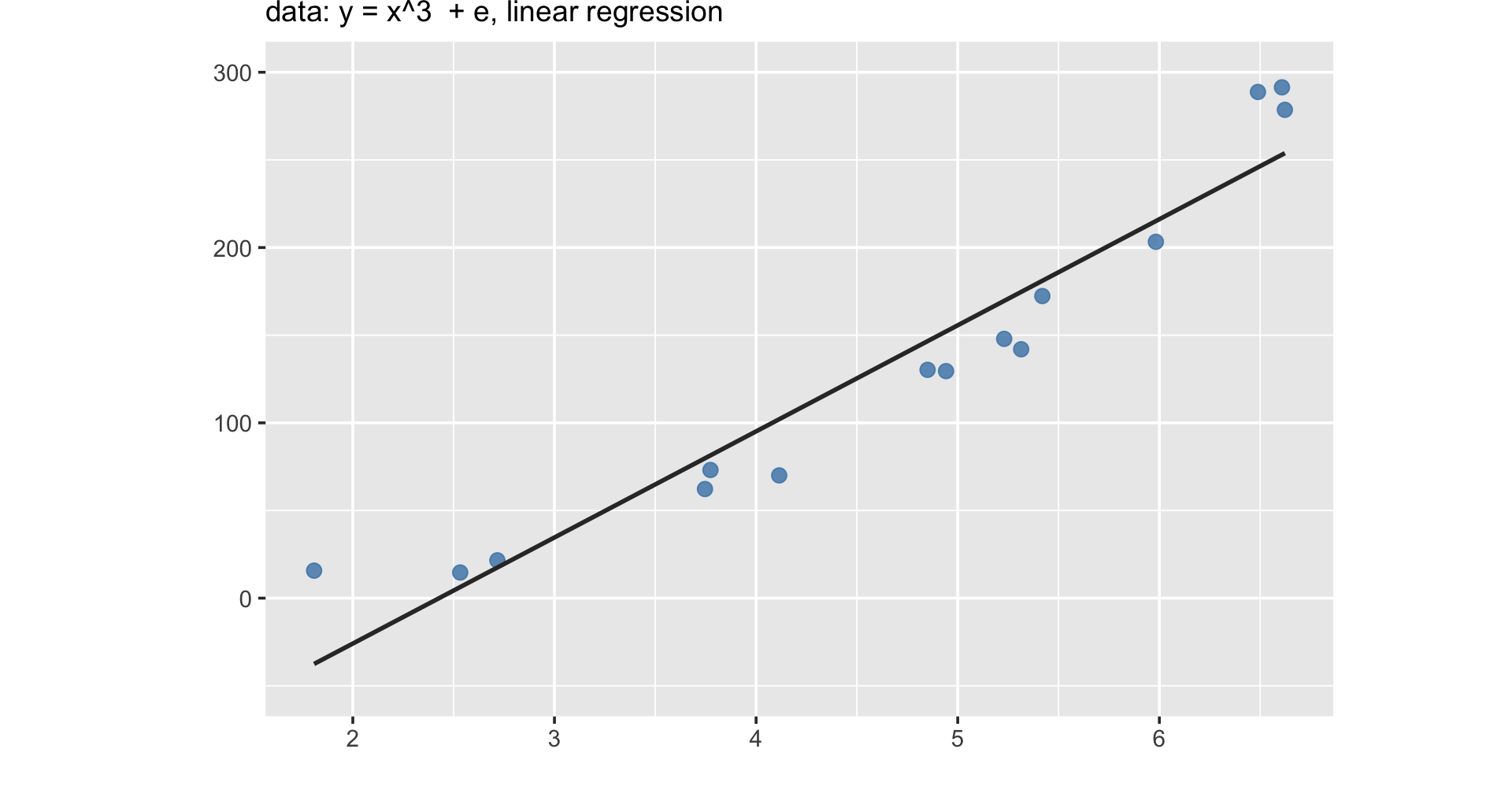
Is about understanding the relationship between one (or several) predictor(s) and an outcome variable
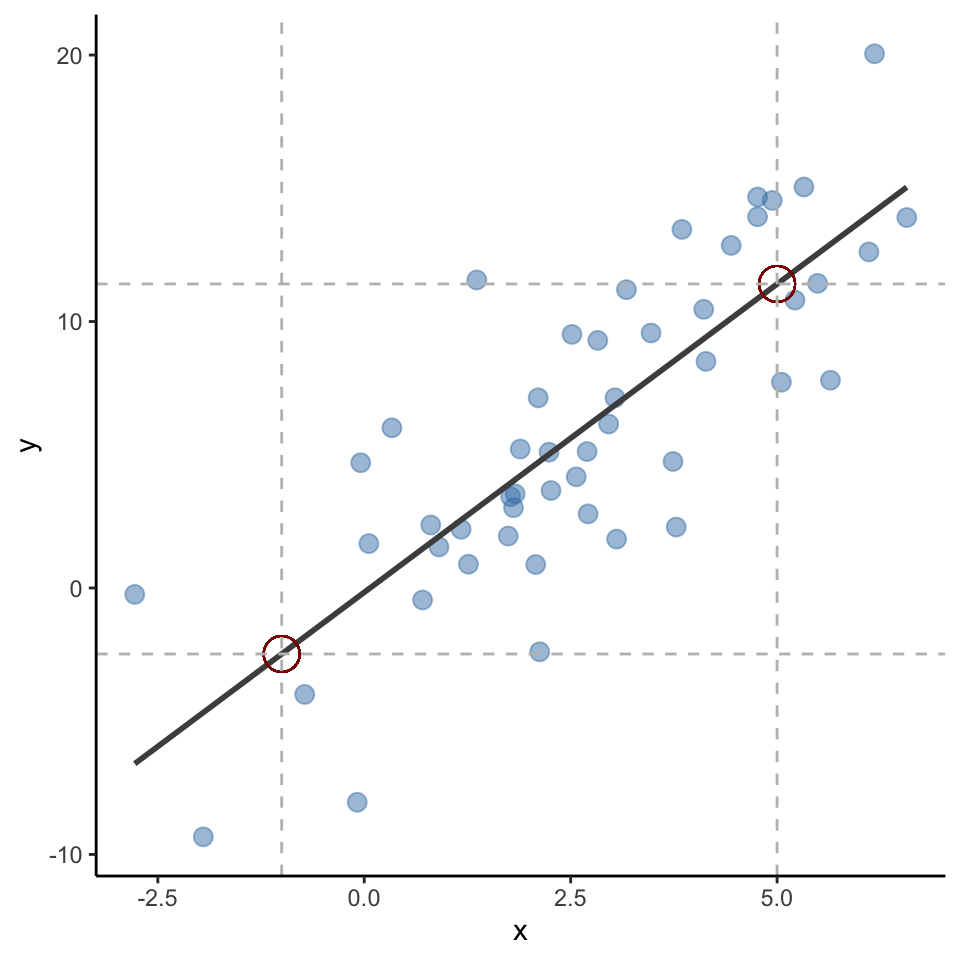
Learn \(f\) so you can predict \(y\) from \(x\):
x increases by 1 unit,y increases by 2.31 units.
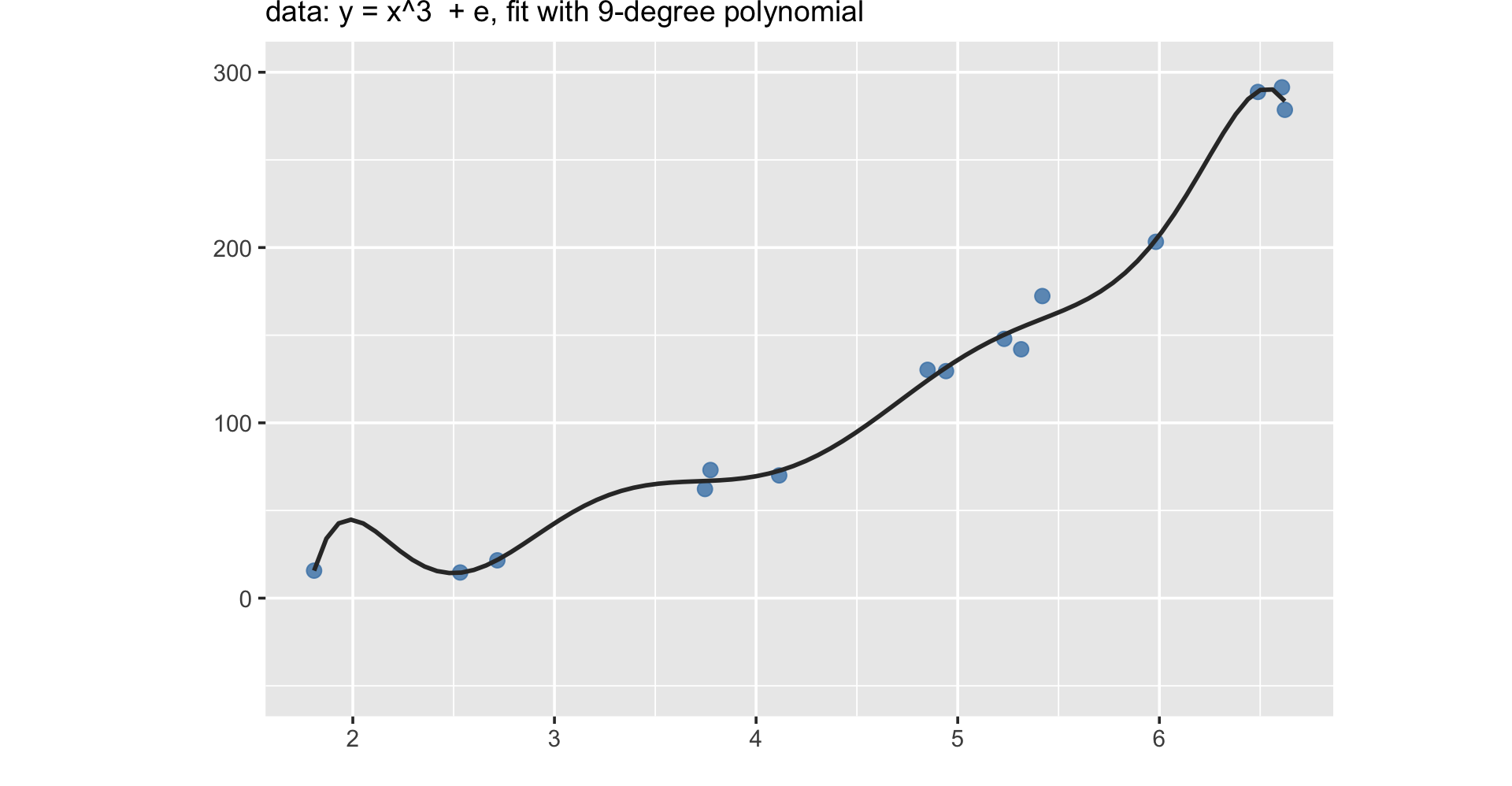
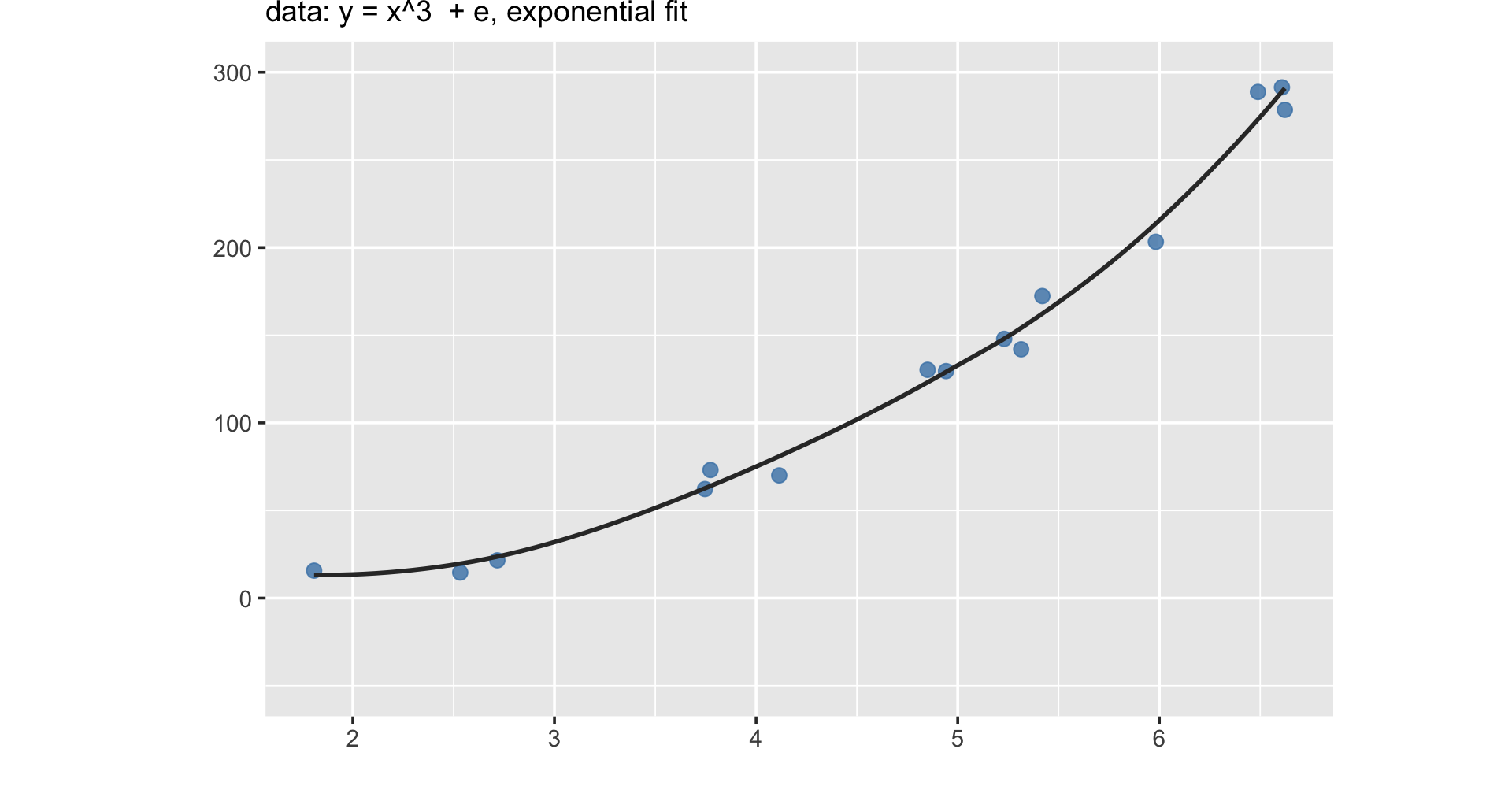
Machine learning less about not understanding, but about maximizing prediction
A statistical model can be used to predict most likely \(y\) values based on new \(x\) data.
For example, despite not being in the data, \(x = -1\) should be \(y = -2.47\); \(x = 5\) should be \(y = 11.41\) based on the fitted line
In other words, machine learning doesn’t focus on explanation, but emphasizes prediction
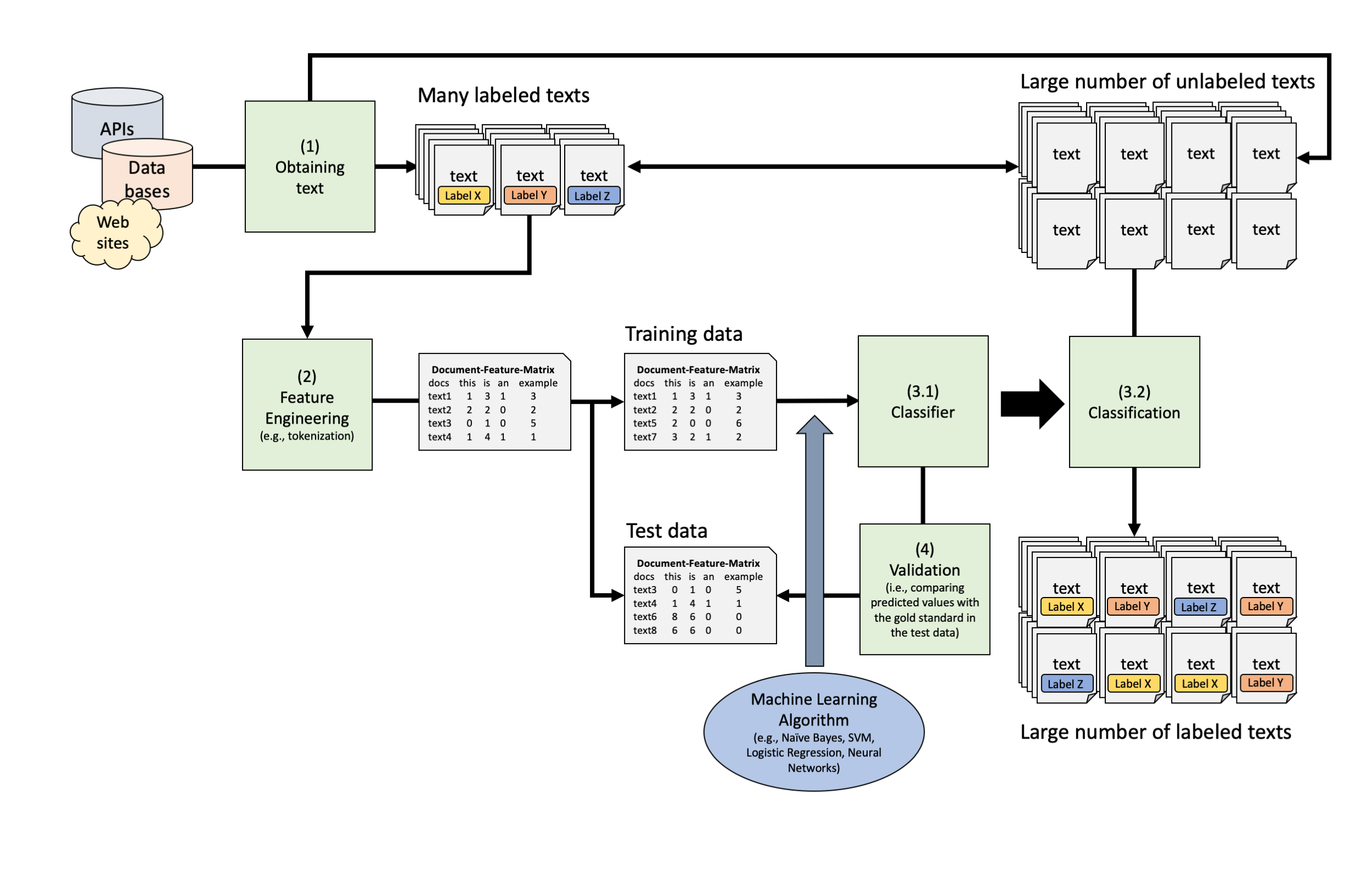
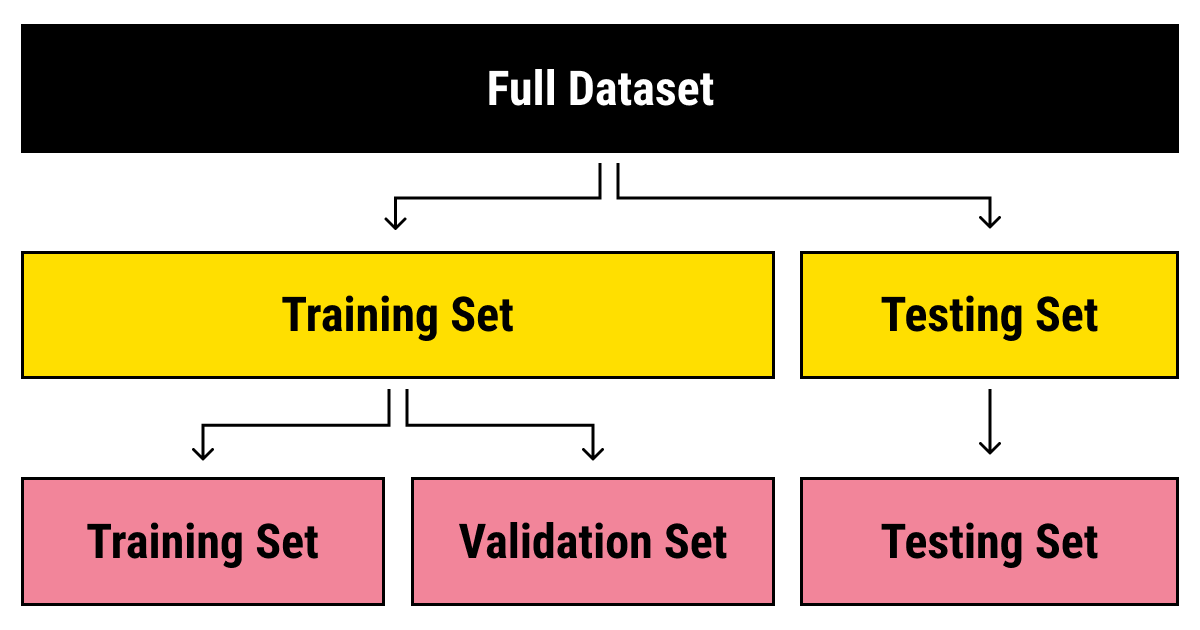
As models (almost) always overfit, performance on only training data is not a good indicator of the real quality of the classifier
The standard solution is to split the labeled data into a training and test data sets: We train the algorithm on one part and then evaluate its performance on the held-out part
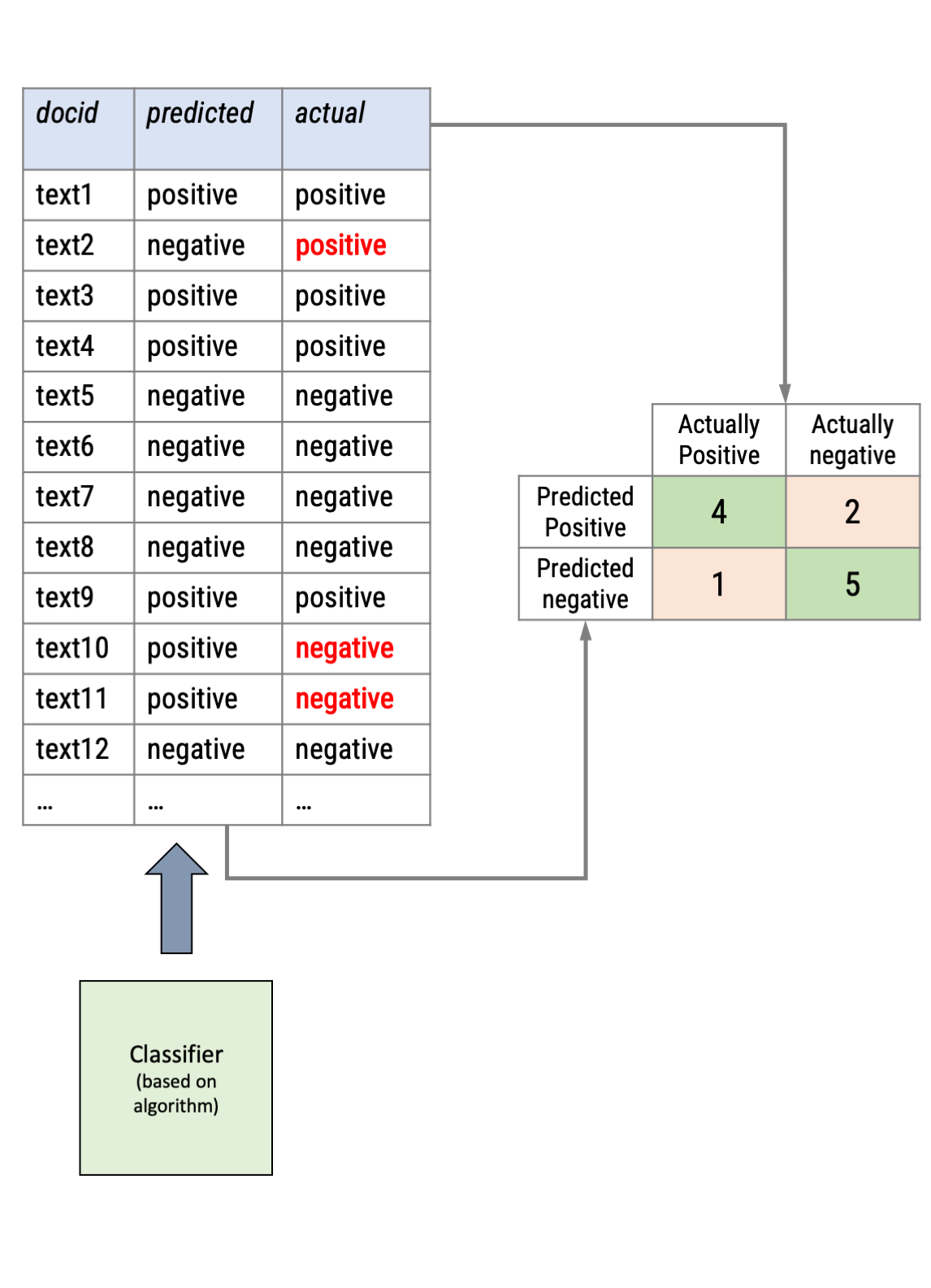
Remember how we validated dictionary approaches?
In supervised text classification, the procedure is similar:
→ In the following, we will focus primarily on neural networks as the most advanced algorithm in ML, but note that we could easily use other algorithms as well
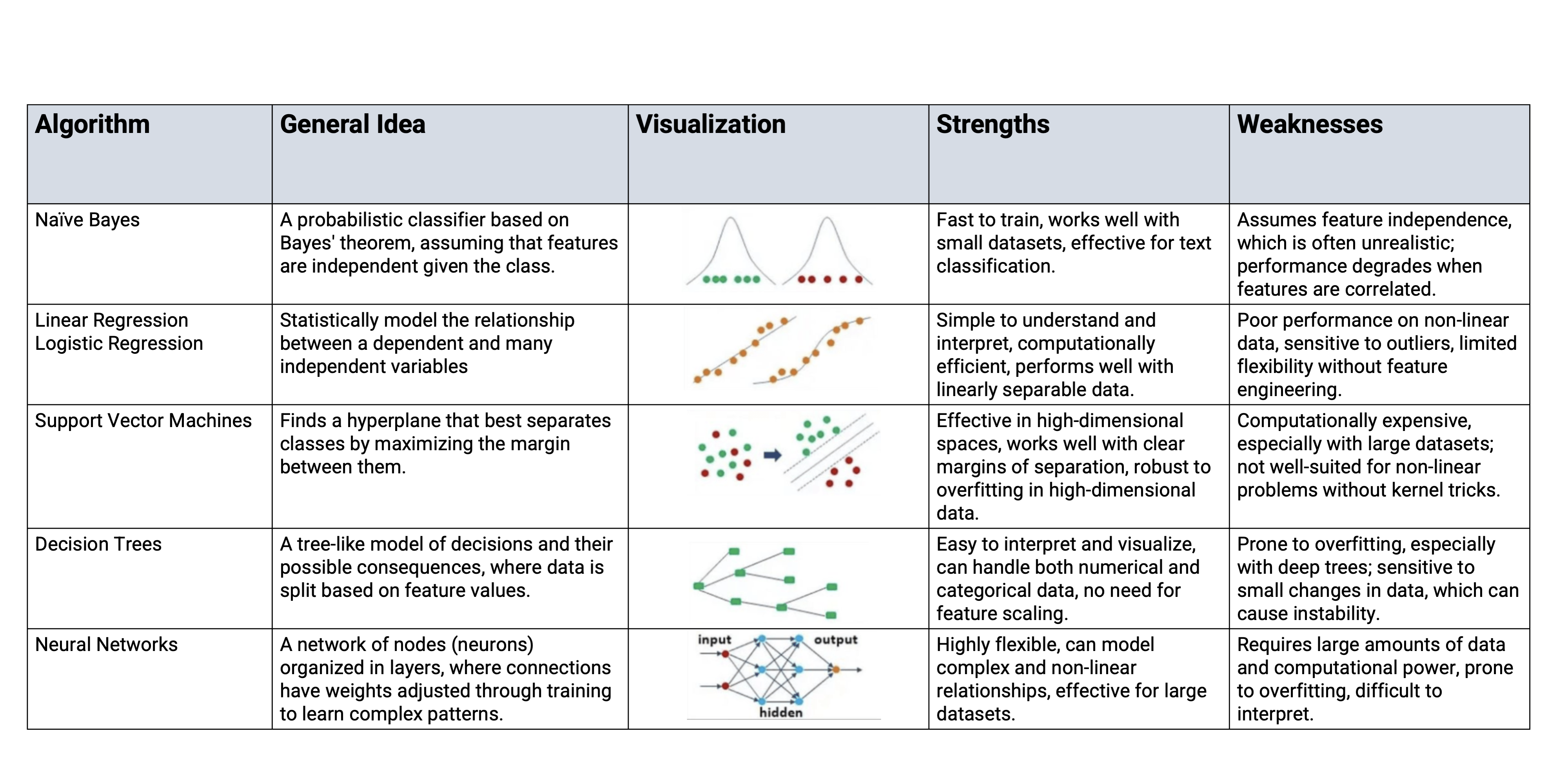
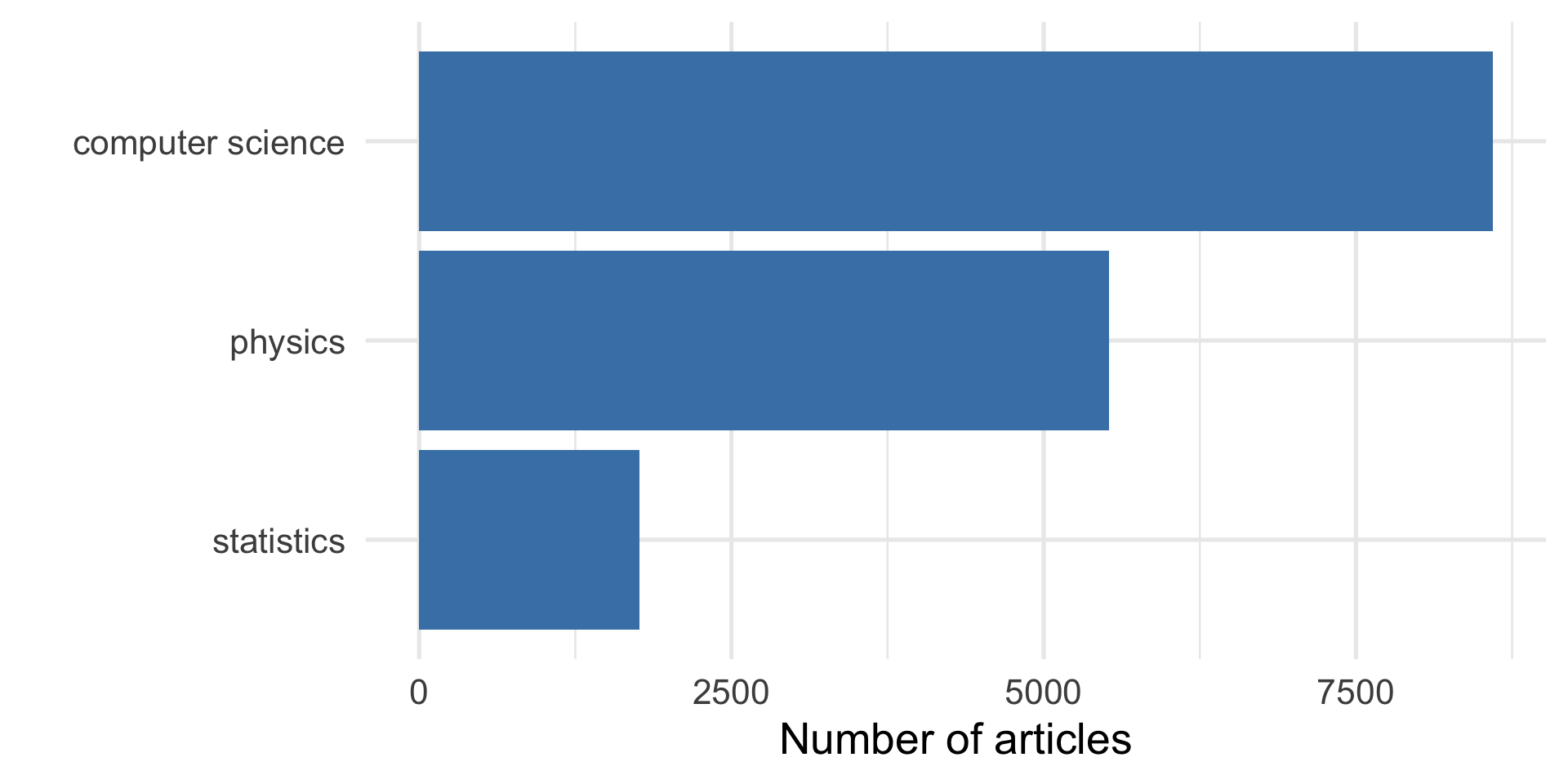
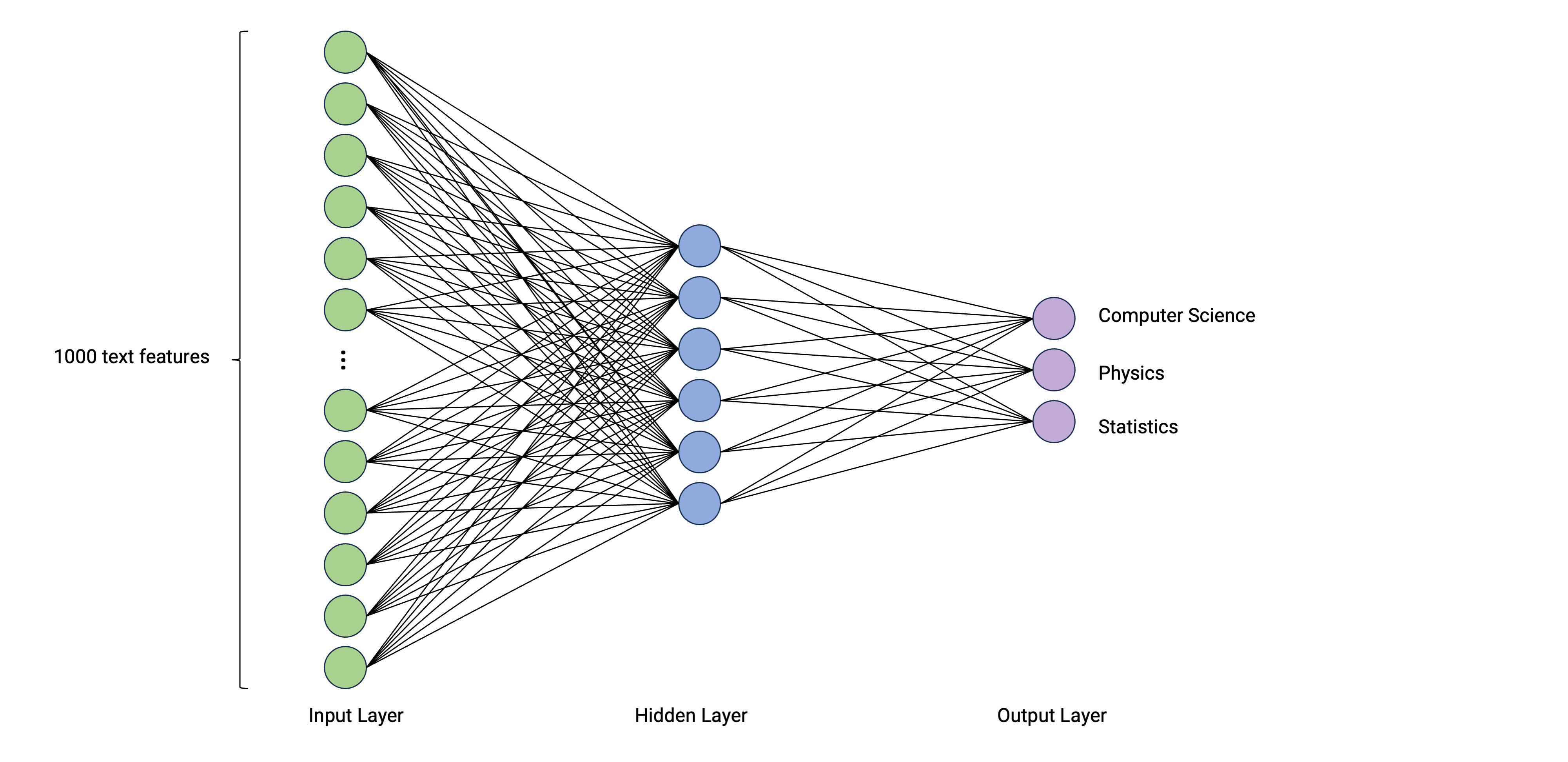
The data contains articles from computer science, physics, and statistics
Our goal is to find a neural network archtecture that can label abstracts with these disciplines sufficiently well
For the entire model fitting process, we are going to use the package tidymodels, which nicely intersects with the already known package tidytext
Here, we can use the functions initial_split to split our data set. The functions training and testing create the actual data sets from the splits.
library(tidymodels)
# Set seed to insure replicability
set.seed(42)
# Create initial split proporations
split <- initial_split(science_data, prop = .90)
# Create training and test data
train_data <- training(split)
test_data <- testing(split)
# Check
tibble(dataset = c("training", "testing"),
n_songs = c(nrow(train_data), nrow(test_data)))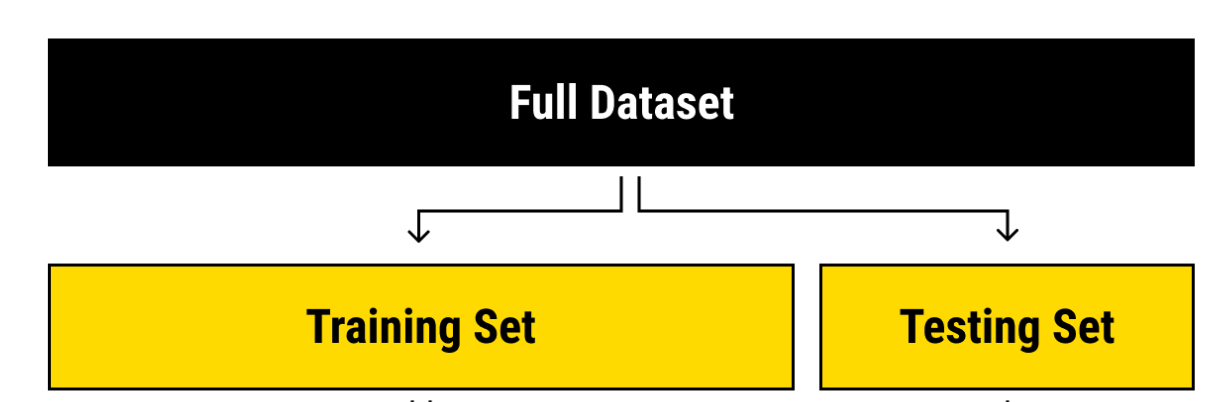
Classic machine learning models require a numerical representation of text (e.g., document-feature matrix)
They further need the outcome variable that they should predict
All text-preprocessing steps (e.g., stopword removal, stemming, frequency trimming,etc.) may change the performance, but no clear rules on what works and what does not
Only solution: Trial and error!

The collection tidymodels contains a variety of packages that facilitates and streamlines machine learning in R
The basic procedure is the following:

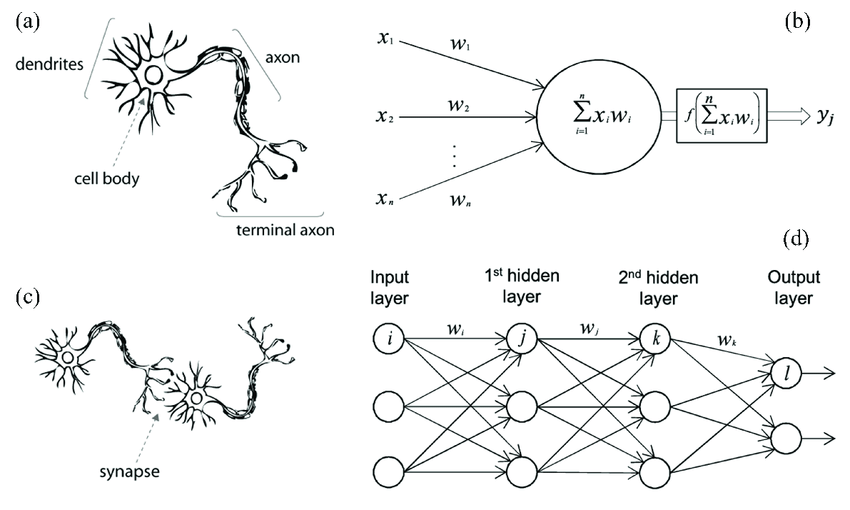
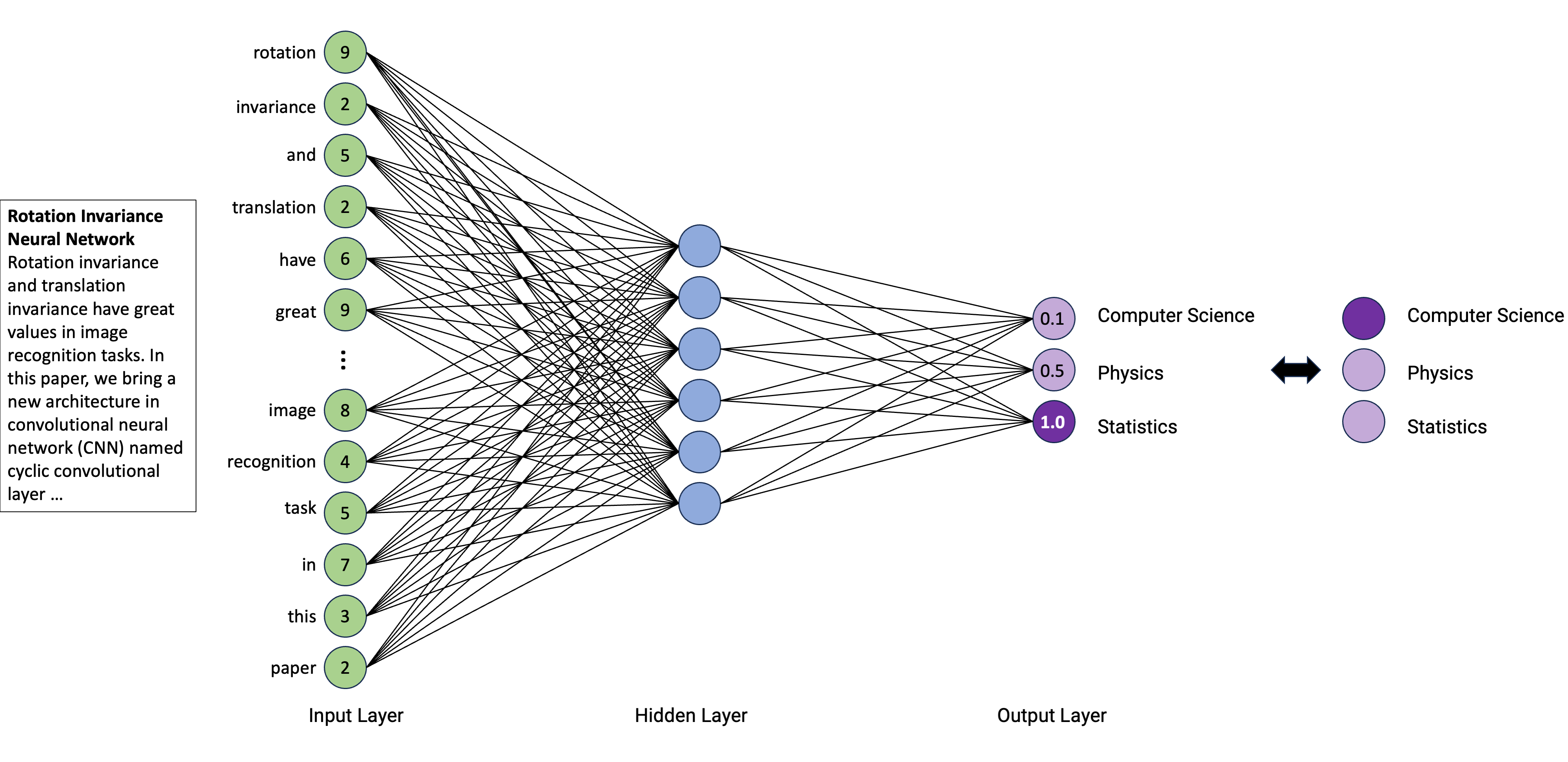
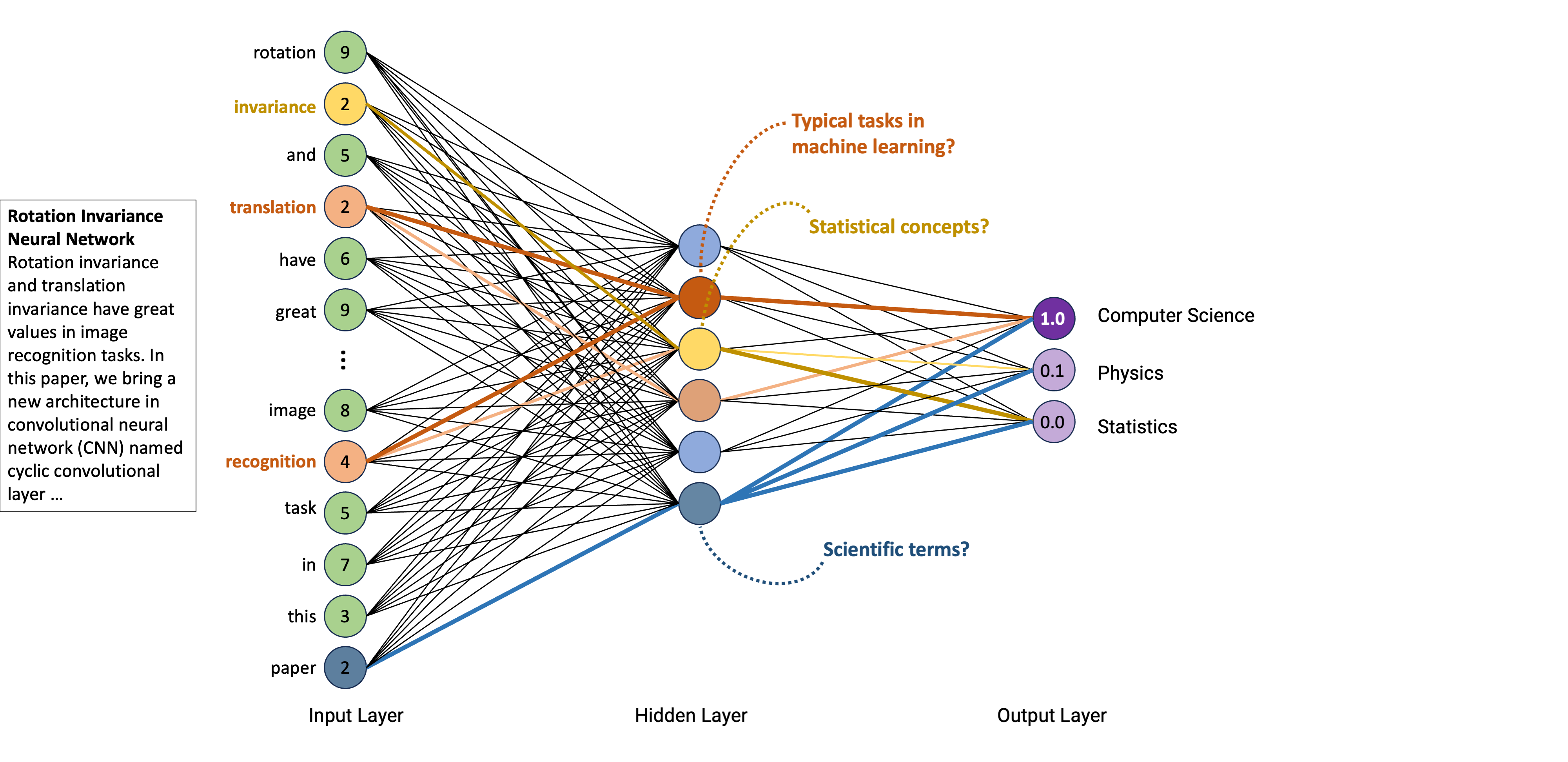
An artificial neural network models the relationship between a set of input signals and an output signal using a model derived from our understanding of the human brain
Like a brain uses a network of interconnected cells called “neurons” (a) to provide fast learning capabilities, a neural network uses a network of artificial neurons (b) to solves learning tasks
Source: Arthur Arnx/Medium
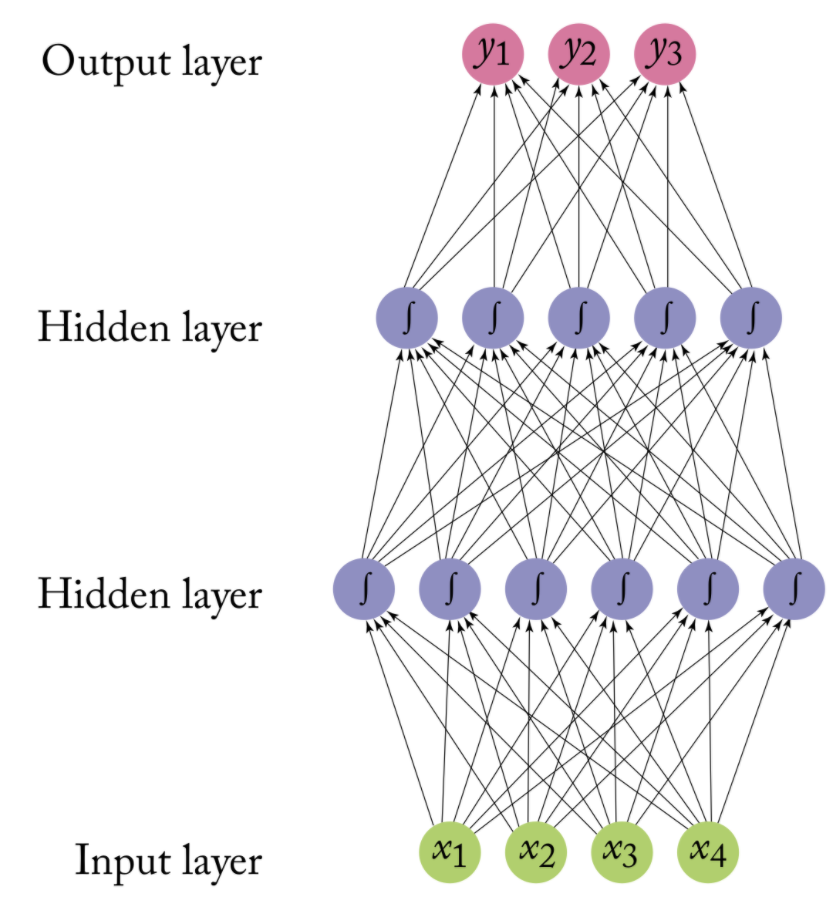
The operation of an artificial neural network is straightforward:
Neurons are stacked on top of one another and a neuron of colum n can only be connected to inputs from column n-1 and provide outputs to neurons in column n+1
In other words, input data are passed through layered transformations until an output is reached
First, the value of each input neuron is multiplied by so-called “weight” (w1, w2, w3), which could be regarded as the strength of connection between two neurons
Second, the neuron adds up the values of every input neuron from the previous column it is connected to (here x1, x2, and x3)
Third, a bias value may be added (e.g., to regularize the network)
After all those summations, the neuron finally applies a function called “activation function” to the obtained value
Source: Arthur Arnx/Medium
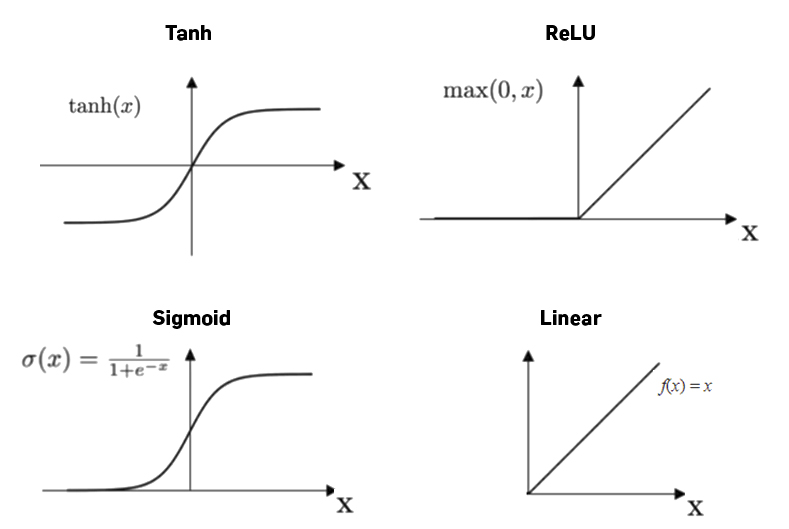
The activation function serves to turn the total value calculated to a number between 0 and 1
A threshold then defines at what value the function should “fire” the output to the next neuron (of course this can be probabilistic)
We can choose from different activation functions; which works best is sometimes hard to tell
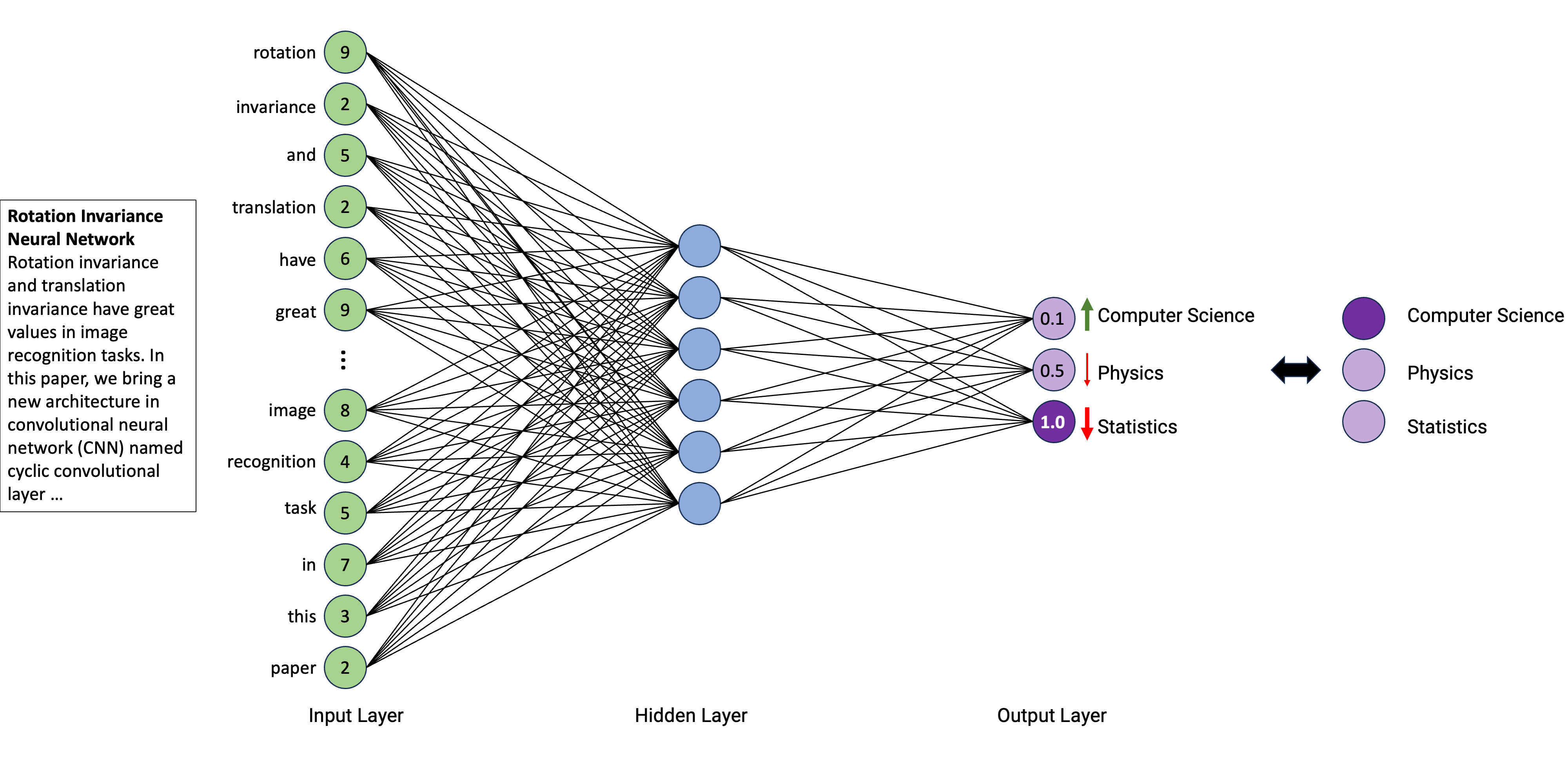
 In a first try, the neural network randomly sets weights and thus can’t get the right output (except with luck)
In a first try, the neural network randomly sets weights and thus can’t get the right output (except with luck)
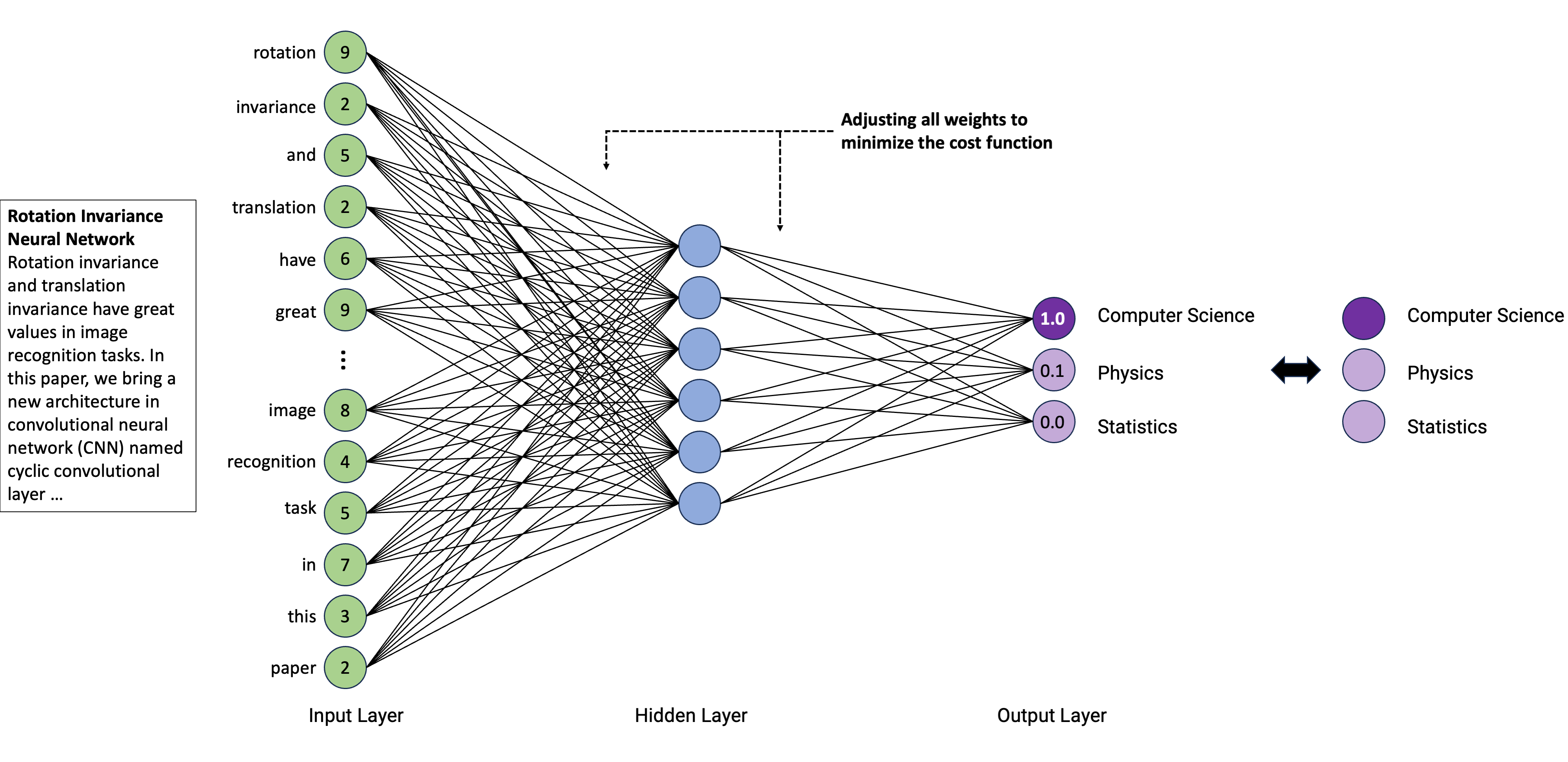
If the random choice was a good one, actual parameters are kept and the next input is given. If the obtained output doesn’t match the desired output, the weights are changed
To determine which weight is better to modify, a neural network uses backpropagation, which consists of “going back” on the neural network and inspect every connection to check how the output would behave according to a change on the weight
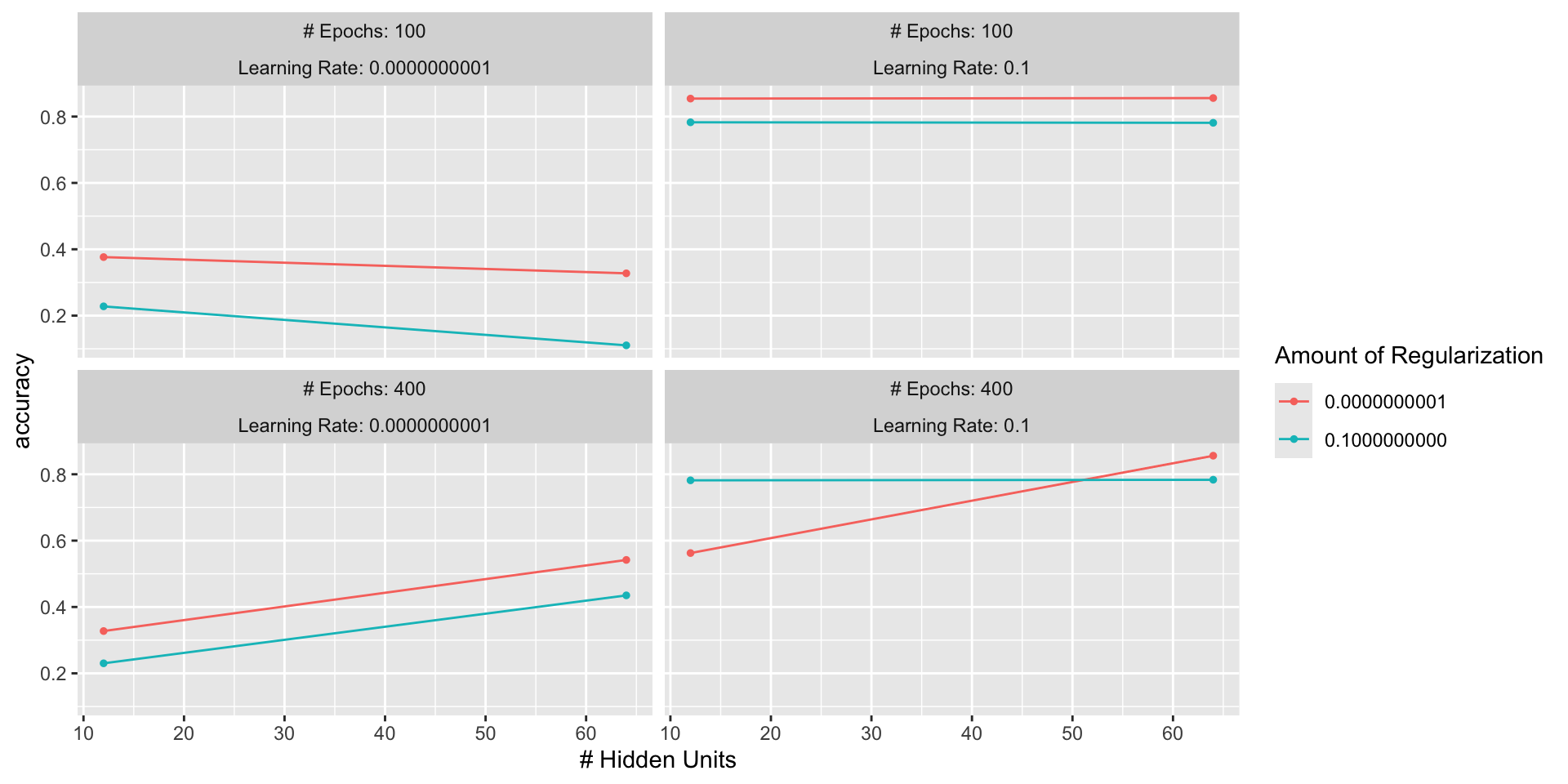
The learning rate thereby determines the speed a neural network will learn, i.e., how it will modify a weight (e.g., little by little or by bigger steps).
Learning rate and number of learning cycles (so-called epochs) have to be set manually upfront!
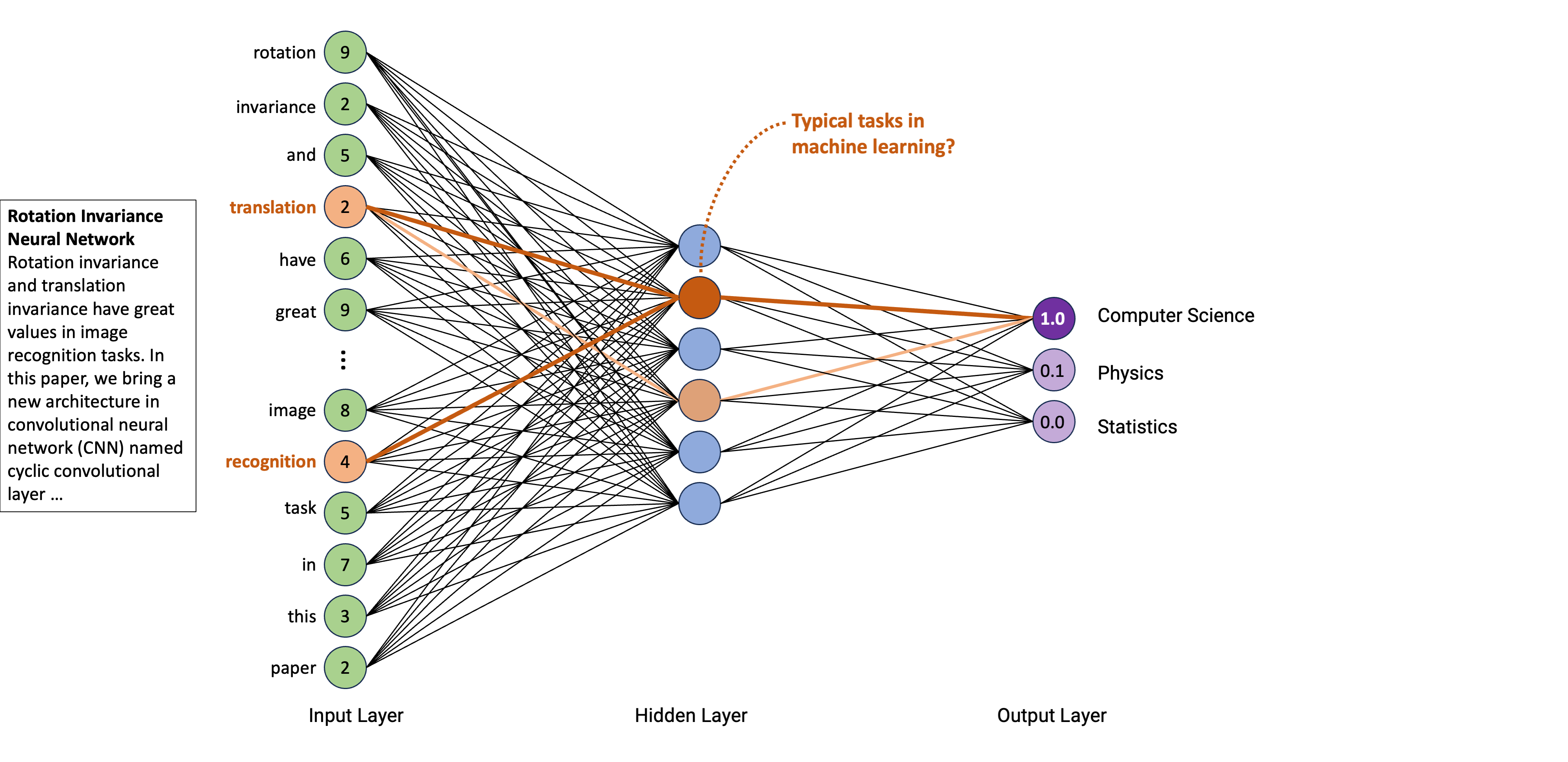
It is hard to imagine how the network has learned that a certain combination of words corresponds to a certain label.
In fact, we can only speculate that it might capture certain meaning by co-occurence of words, e.g., that certain words are representing machine learning and machine learning, in turn, is most likely to be within “computer science”

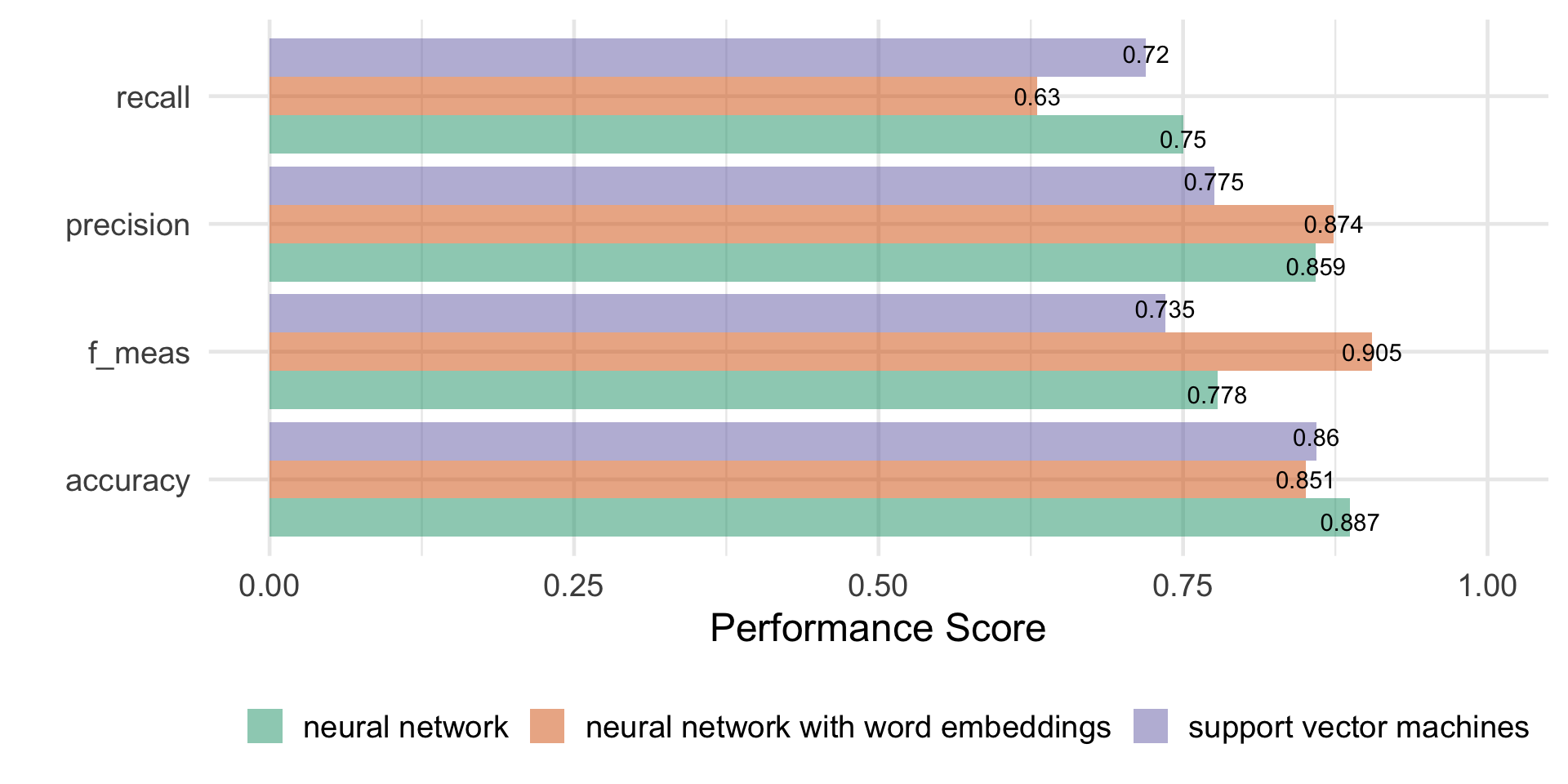
# Predict test data
predict_svm <- predict(m_svm, new_data=test_data) |>
bind_cols(test_data) |>
mutate(truth = factor(label)) |>
select(id, predicted = .pred_class, truth, title)
# Combine predict data from SVM and neural network
bind_rows(
# Compute class_metrics for SVM
predict_svm |>
class_metrics(truth=truth, estimate=predicted) |>
mutate(algorithm = "support vector machines"),
# Compute class_metrics for NN
predict_ann |>
class_metrics(truth=truth, estimate=predicted) |>
mutate(algorithm = "neural network")) |>
# Plot comparison
ggplot(aes(x = .metric, y = .estimate,
fill = algorithm)) +
geom_col(position=position_dodge(), alpha=.5) +
geom_text(aes(label = round(.estimate, 3)),
position = position_dodge(width=1)) +
ylim(0, 1) +
coord_flip() +
scale_fill_brewer(palette = "Dark2") +
theme_minimal(base_size = 18) +
theme(legend.position = "bottom") +
labs(y = "Performance Score", x = "", fill = "")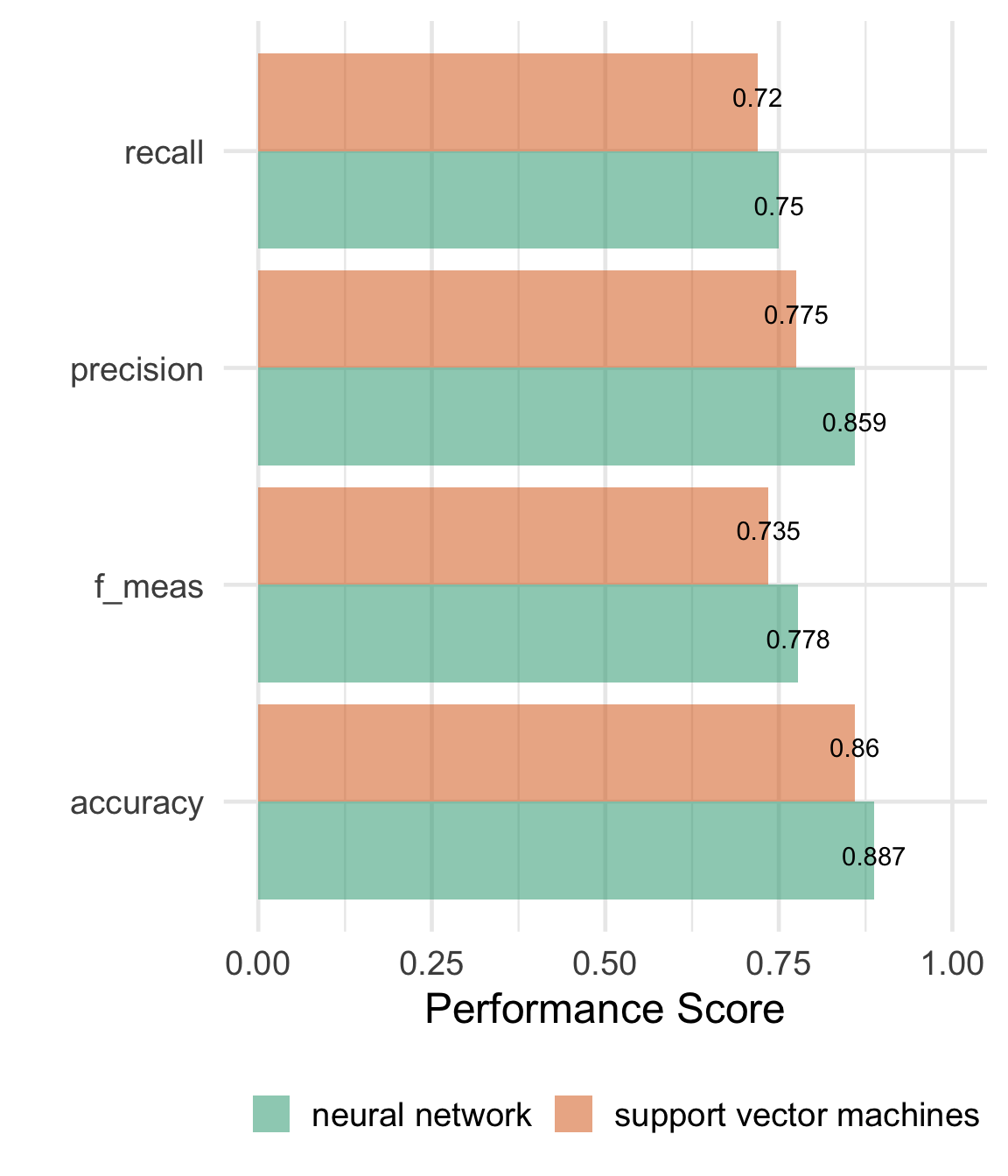
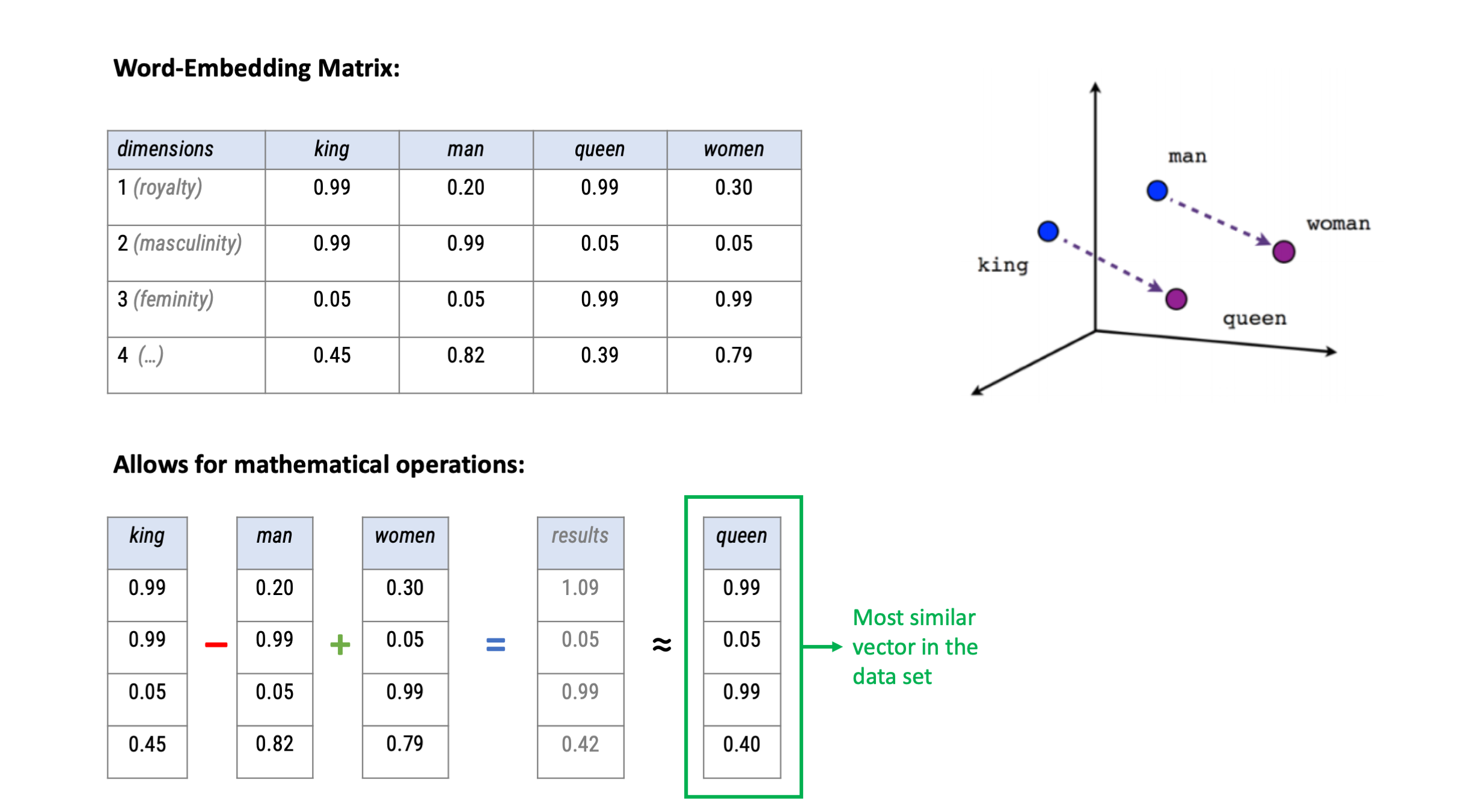
Computers don’t read text, they only can deal with numbers
For this reason, so far, we tokenized our texts (e.g., in words) and summarized their frequency across texts to create a document-feature matrix within the bag-of-words model
Such a text representation has some issues:
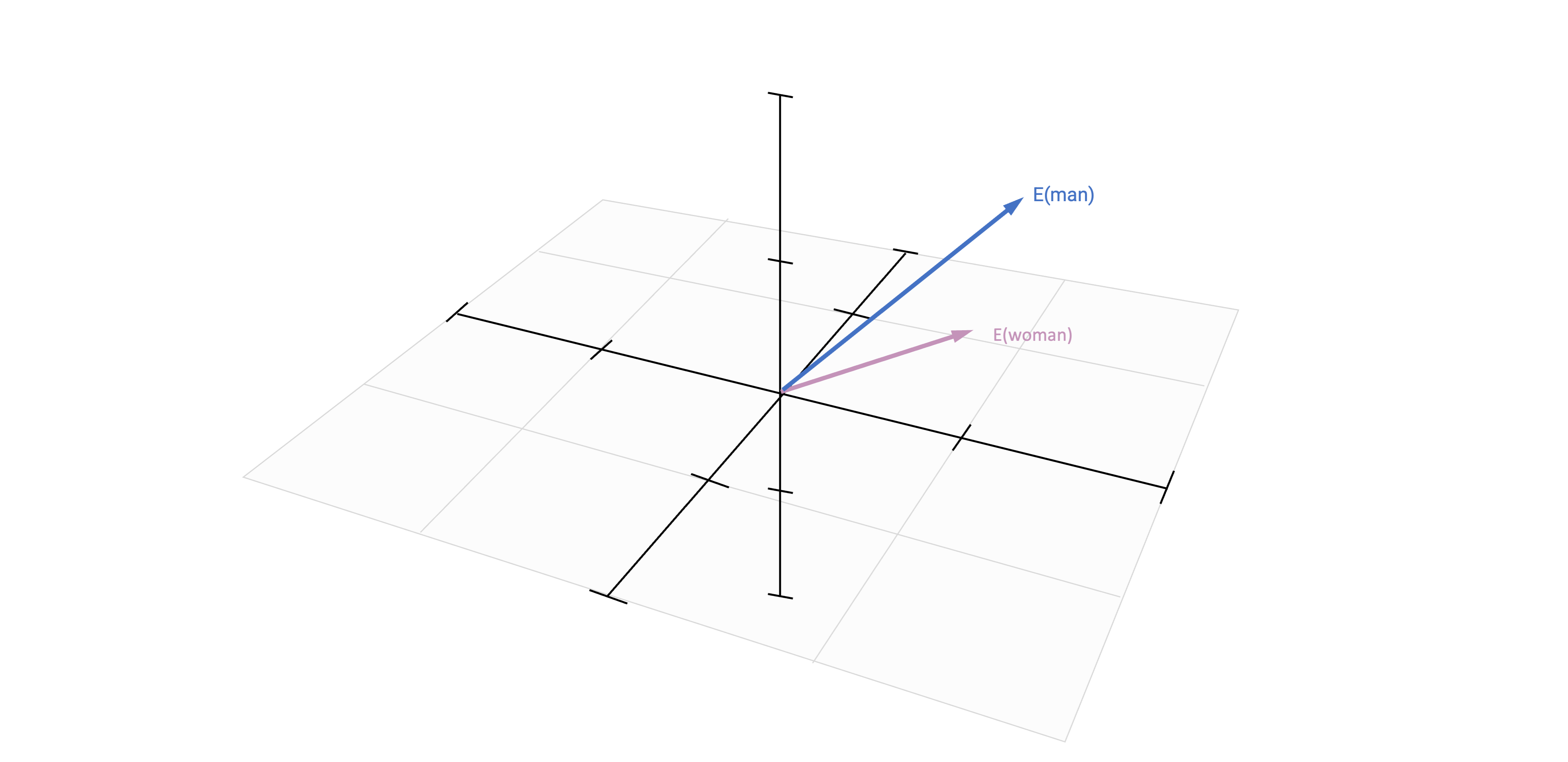
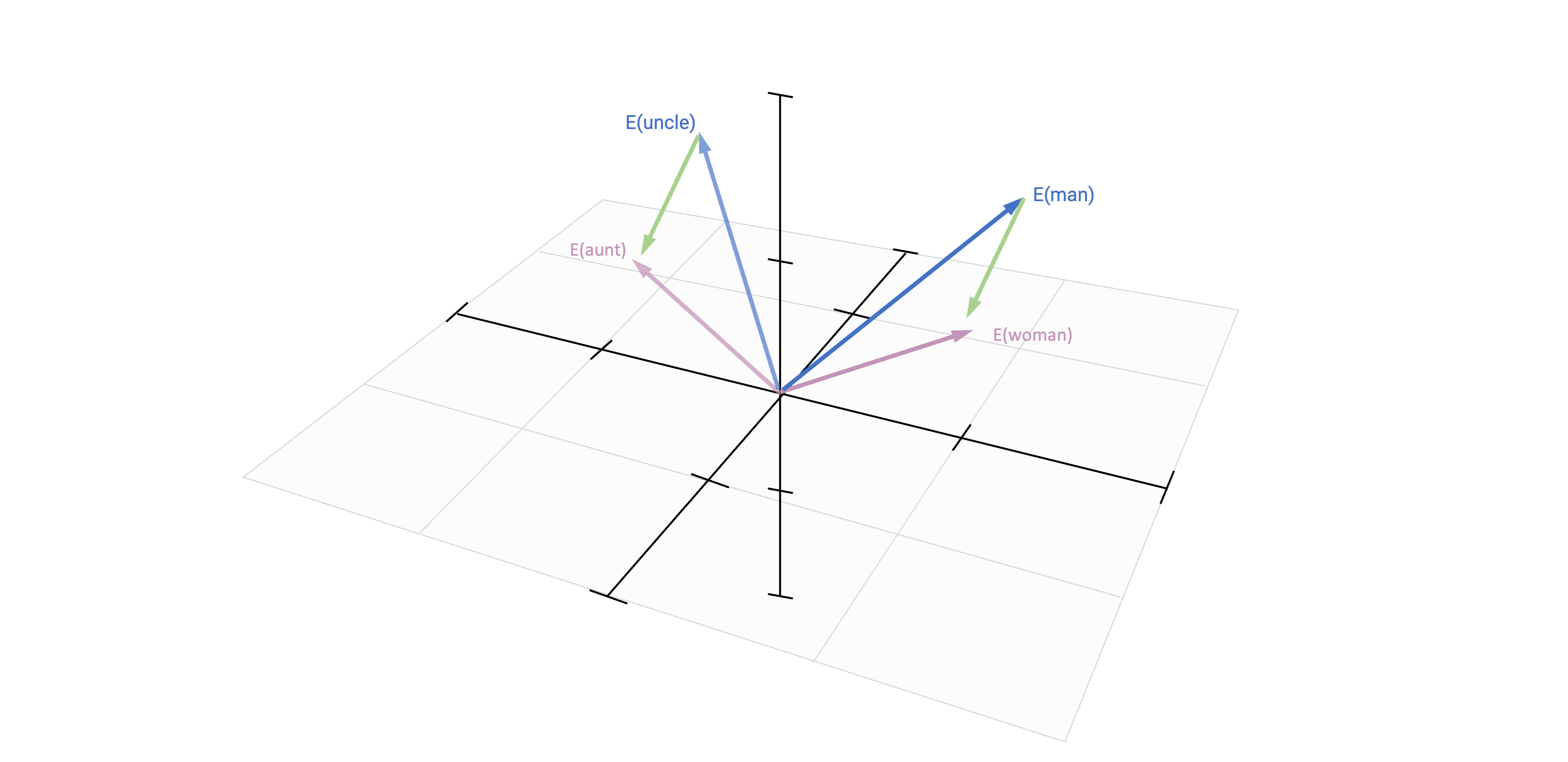
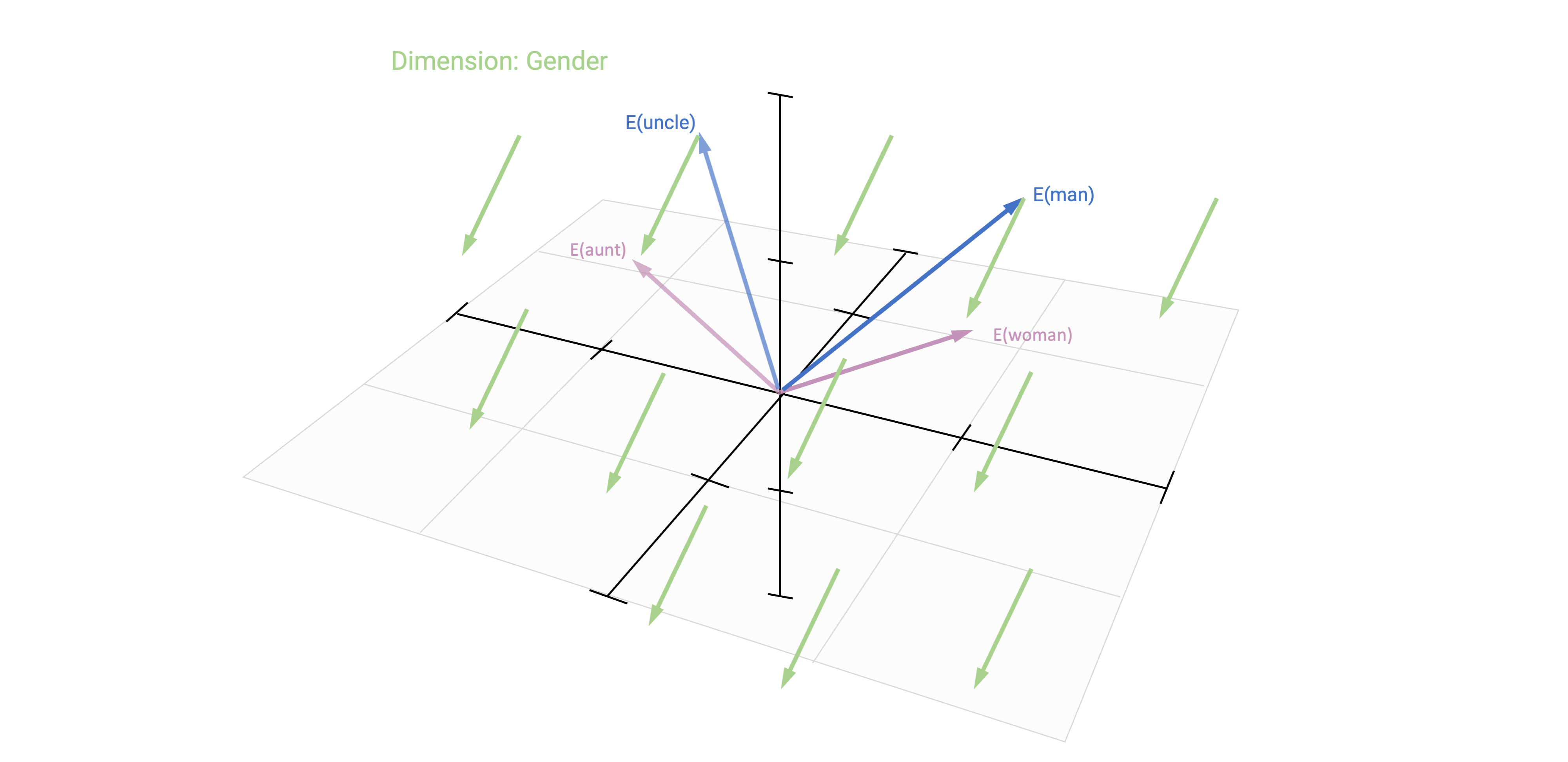
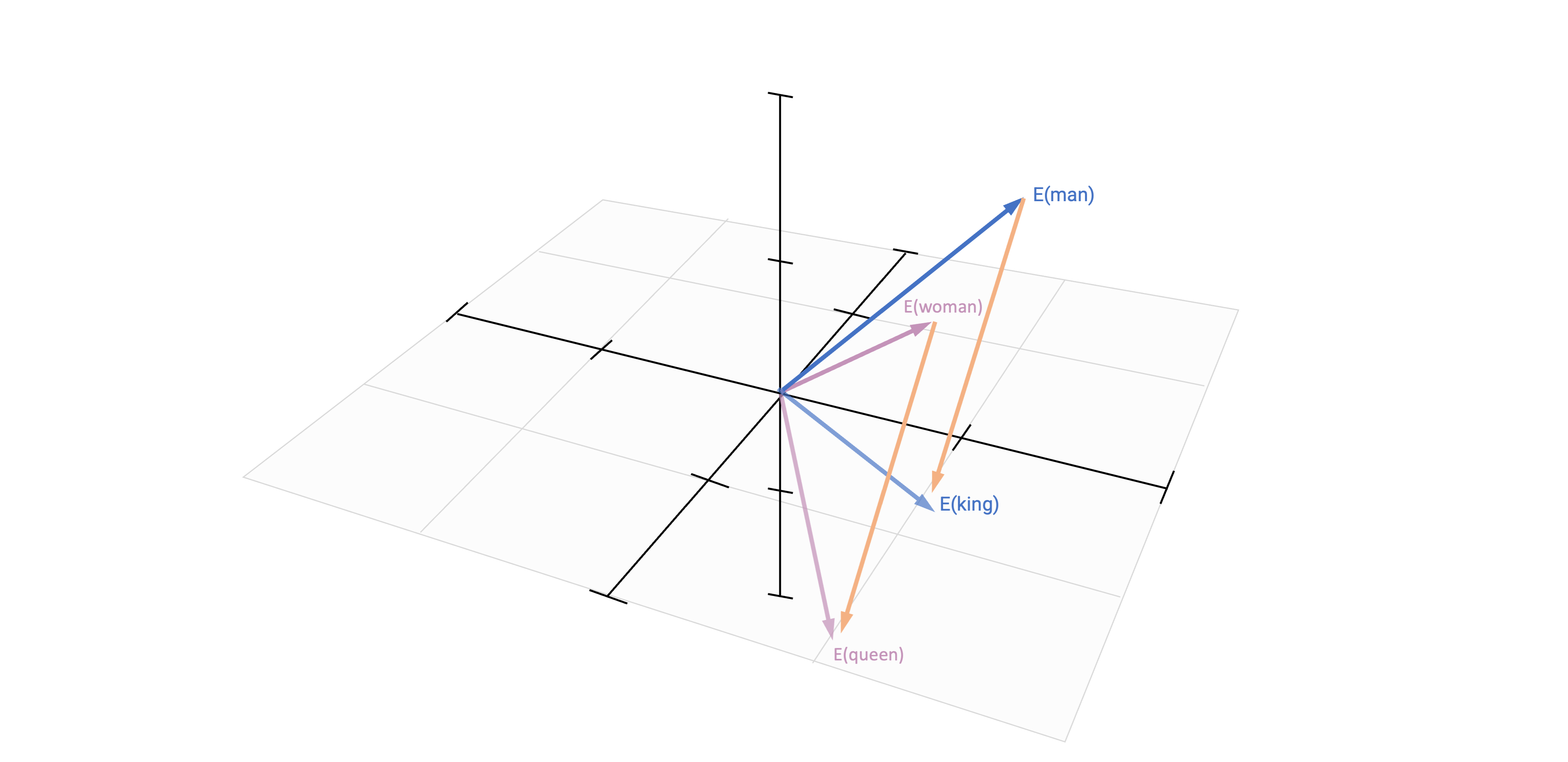
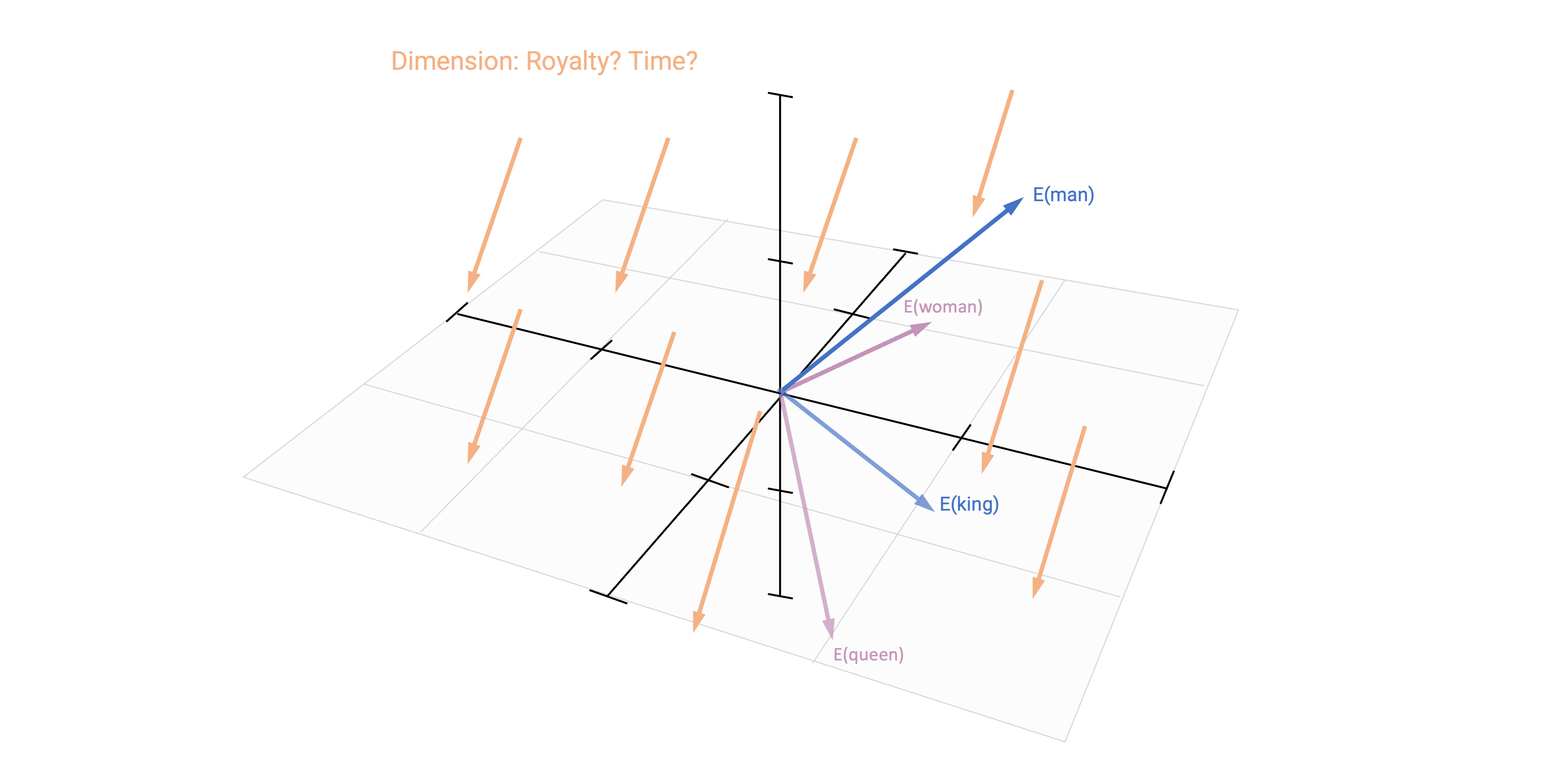
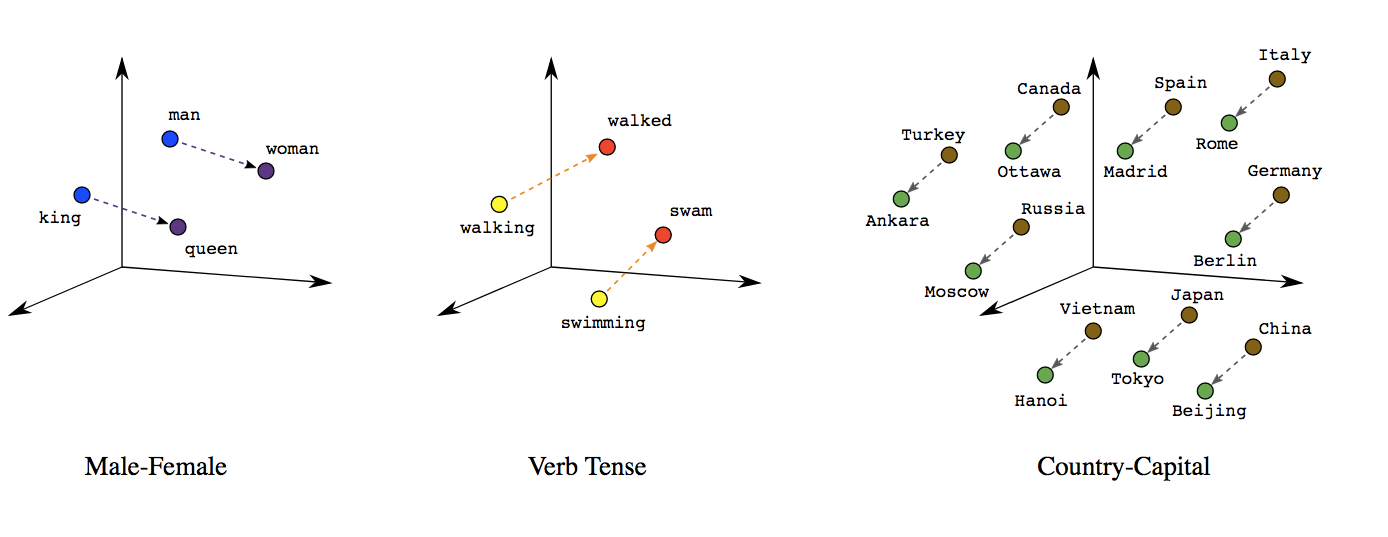
Based on vector-based computations, we can analyse semantic relationships
This is a quite common approach by now in research on gender and other types of stereotypes
Source: https://developers.google.com
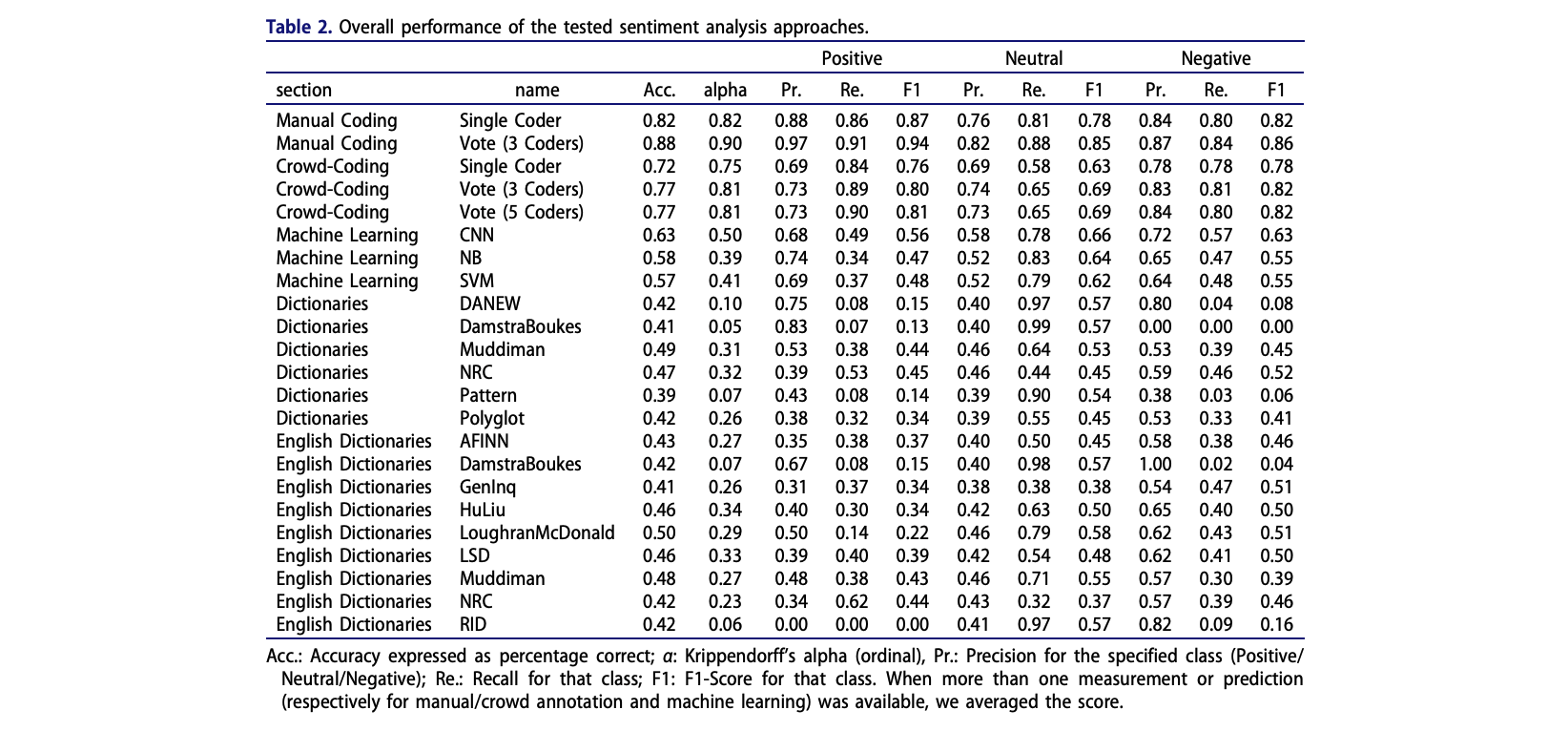
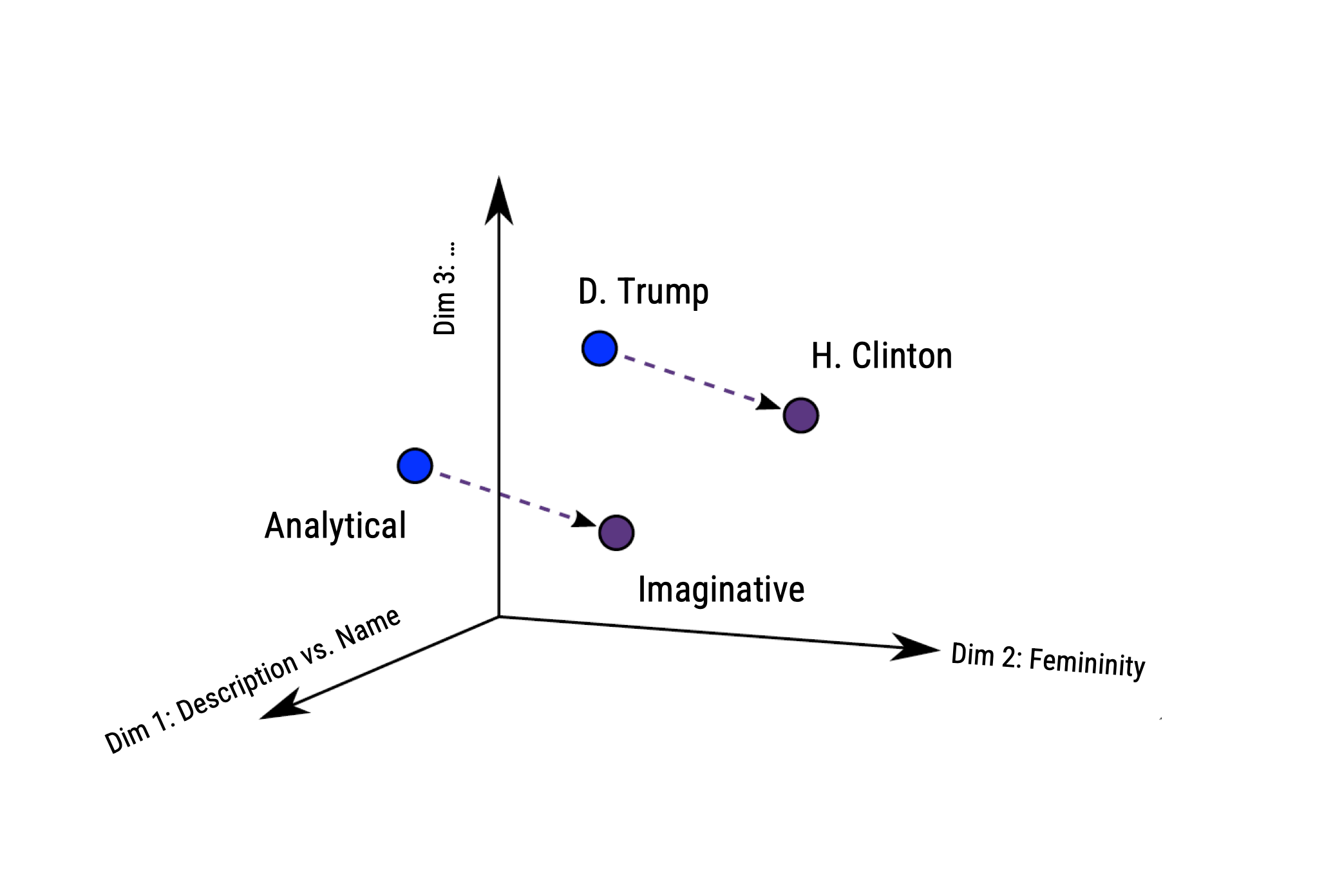 Andrich et al. (2023) examine stereotypical traits in portrayals of 1,095 U.S. politicians.
Andrich et al. (2023) examine stereotypical traits in portrayals of 1,095 U.S. politicians.
Analyzed 5 million U.S. news stories published from 2010 to 2020 to study gender-linked (feminine, masculine) and political (leadership, competence, integrity, empathy) traits
Methodologically, they estimated word embeddings using the Continuous Bag of Words (CBOW) model, meaning that a target word (e.g., honest) is predicted from its context (e.g., Who thinks President Trump is [target word]?)
Bias can thus be identified if e.g., gender-neutral words (e.g., competent) are closer to words that represent one gender (e.g., donald_trump) than to words that represent the opposite gender (e.g., hillary_clinton).
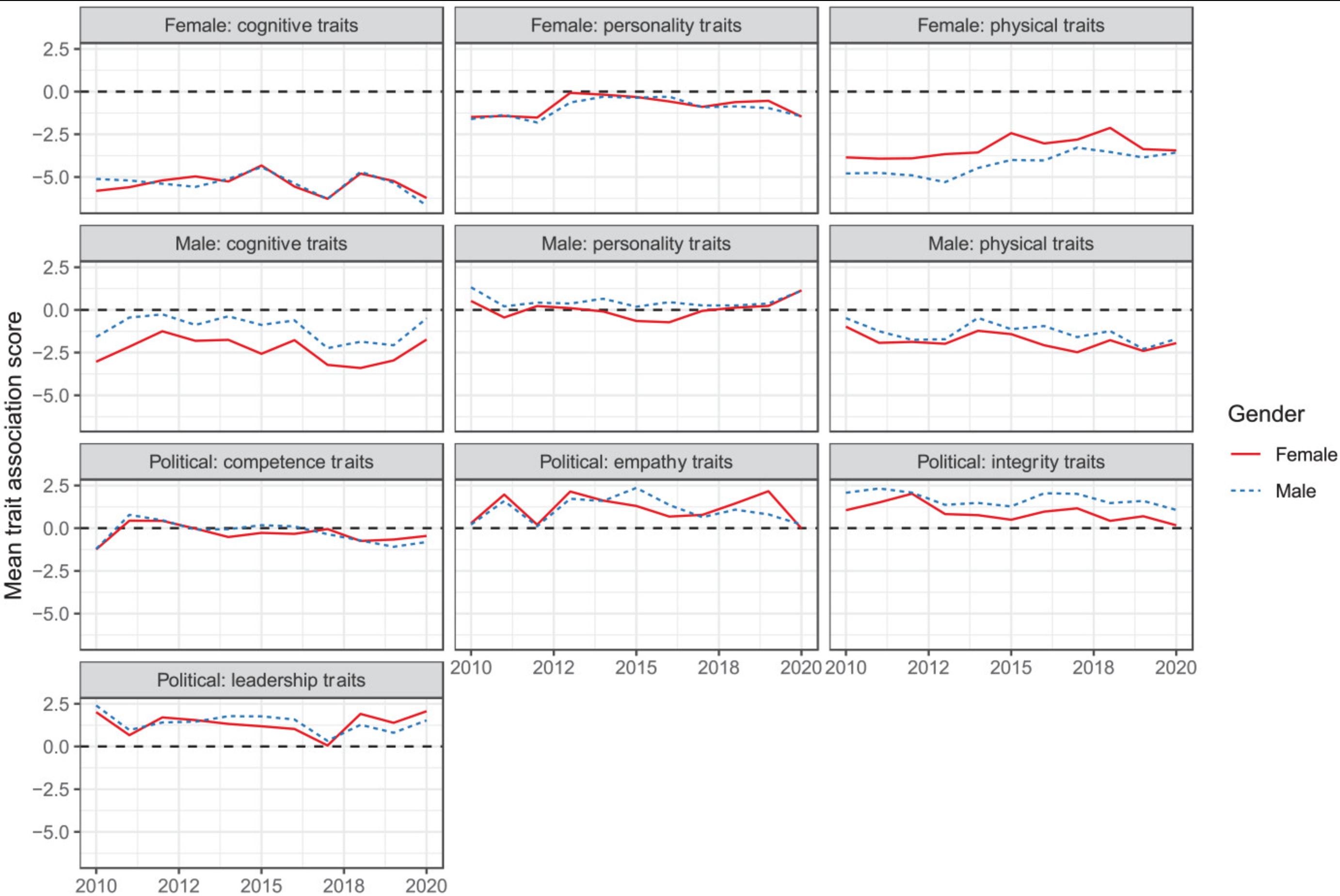
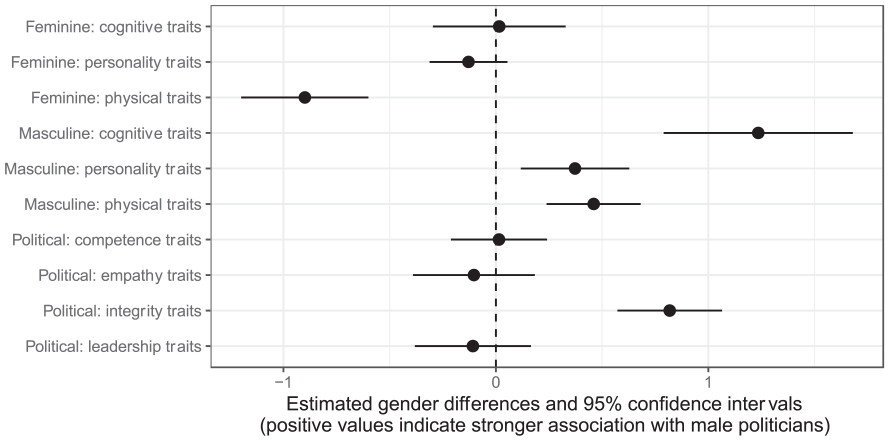
All three masculine traits were more strongly associated with male politicians.
In contrast, only the feminine physical traits were more strongly associated with female politicians.
Differences remained stable across time.
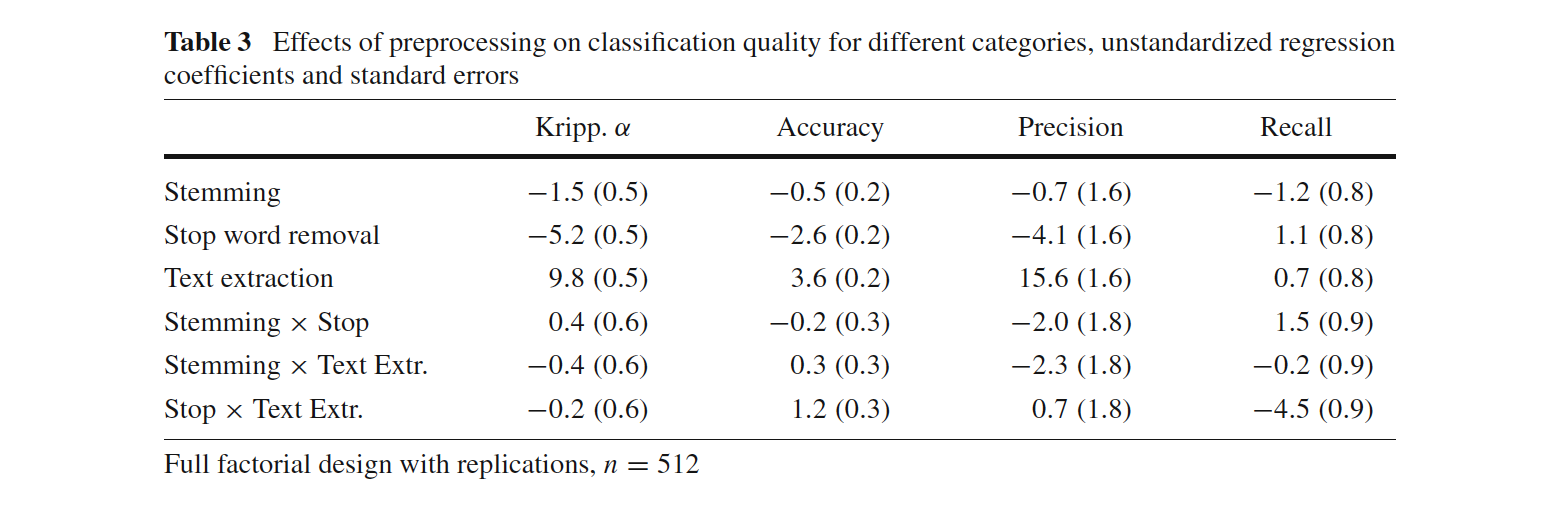
Scharkow ran a simple simulation study in which he systematically varied text preprocessing
The classifier was always Naive Bayes, below we see the average difference in performance
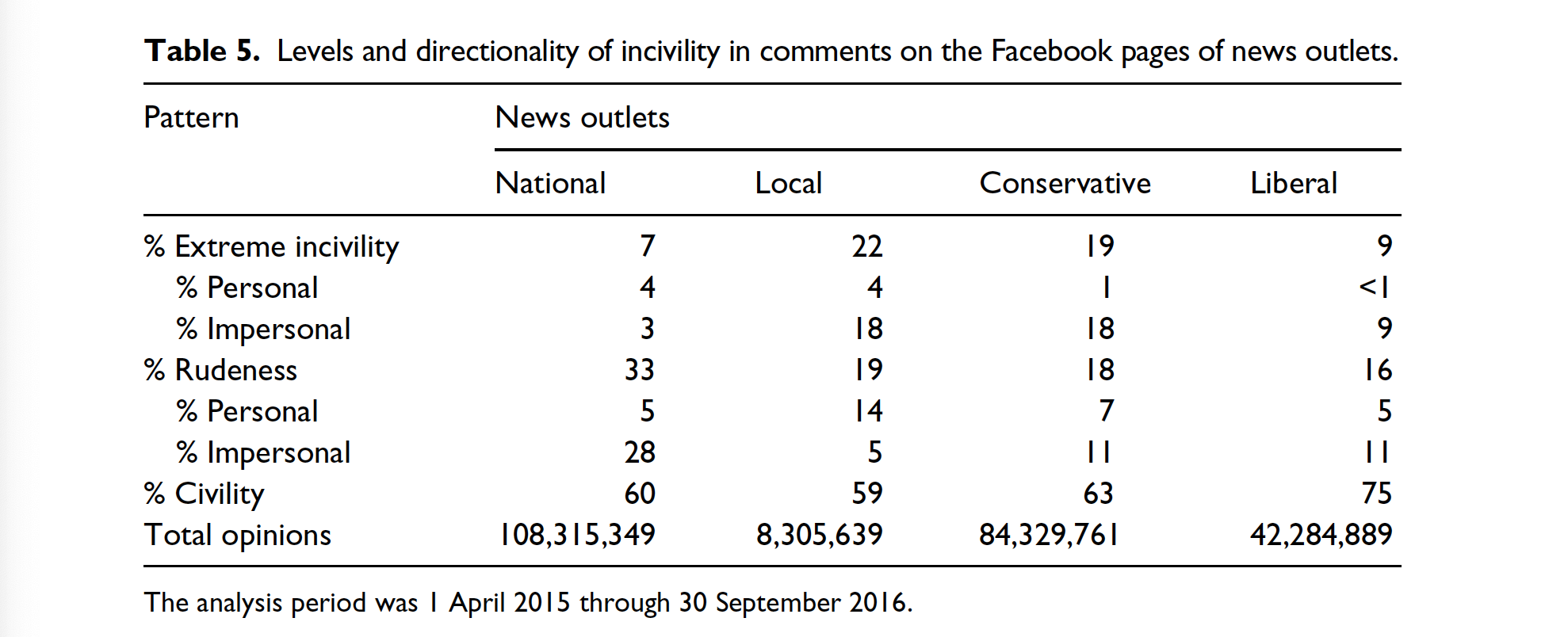
de León et al. (2021) explored how elections transform news sharing behaviour on Facebook
They investigated changes in news coverage and news sharing behaviour on Facebook
Employed a novel data set of news articles (N = 83,054) in Mexico
First coded 2,000 articles manually into topics (Politics, Crime and Disasters, Culture and Entertainment, Economic and Business, Sports, and Other), then used support vector machines to classify the rest

During periods of heightened political activity, both the publication and dissemination of political news increases
The gap between the news choices of journalists and consumers narrows, and increased political news sharing leading to a decrease in the sharing of other news.
Classic machine learning is a useful tool for generalizing from a sample
It is very useful to reduce the amount of manual coding needed
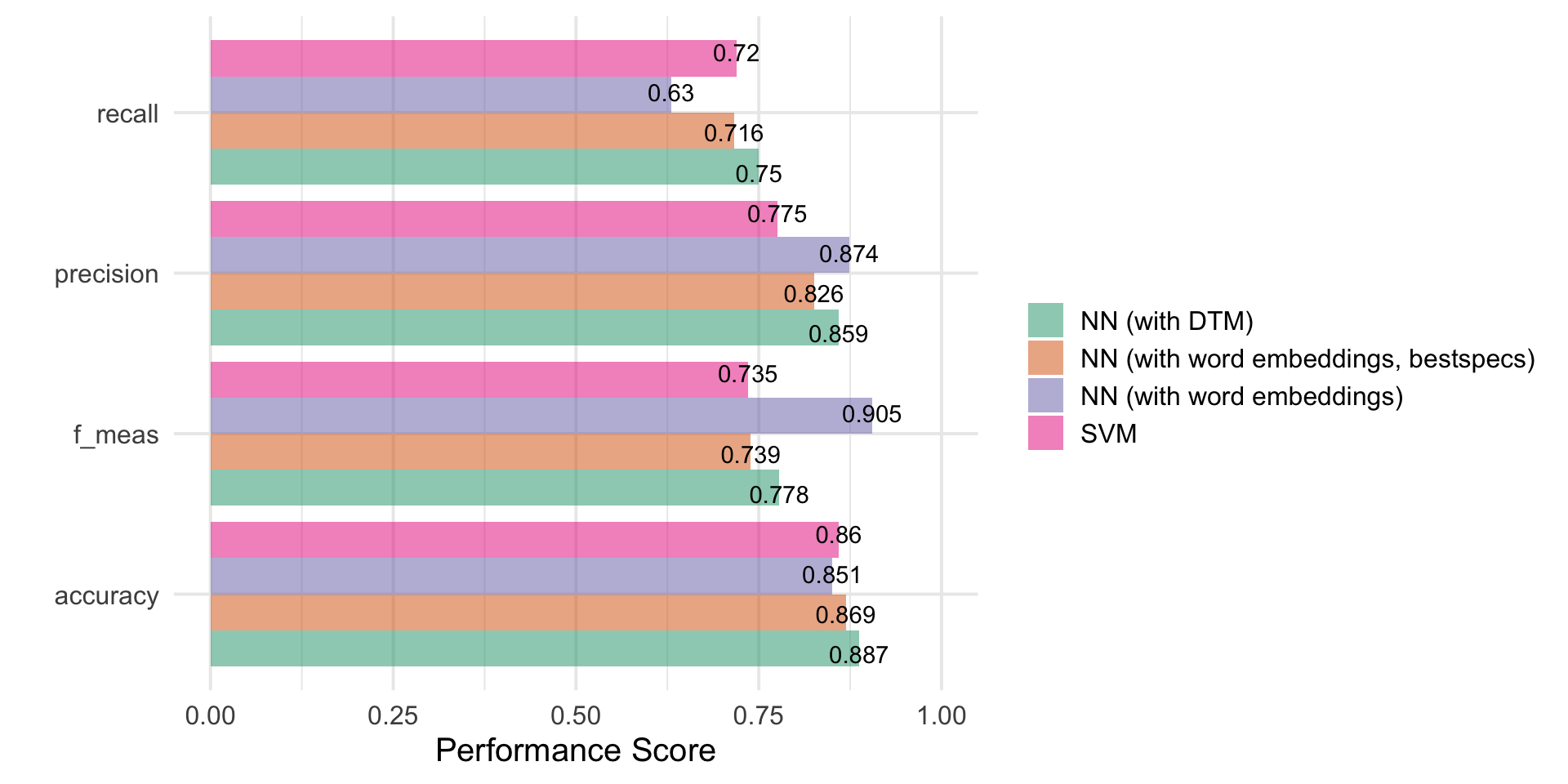
Word-Embeddings are a dense representation of text that can improve speed and performance of standard ML approaches
That said, the field has moved on and innovations are fast-paced these days:

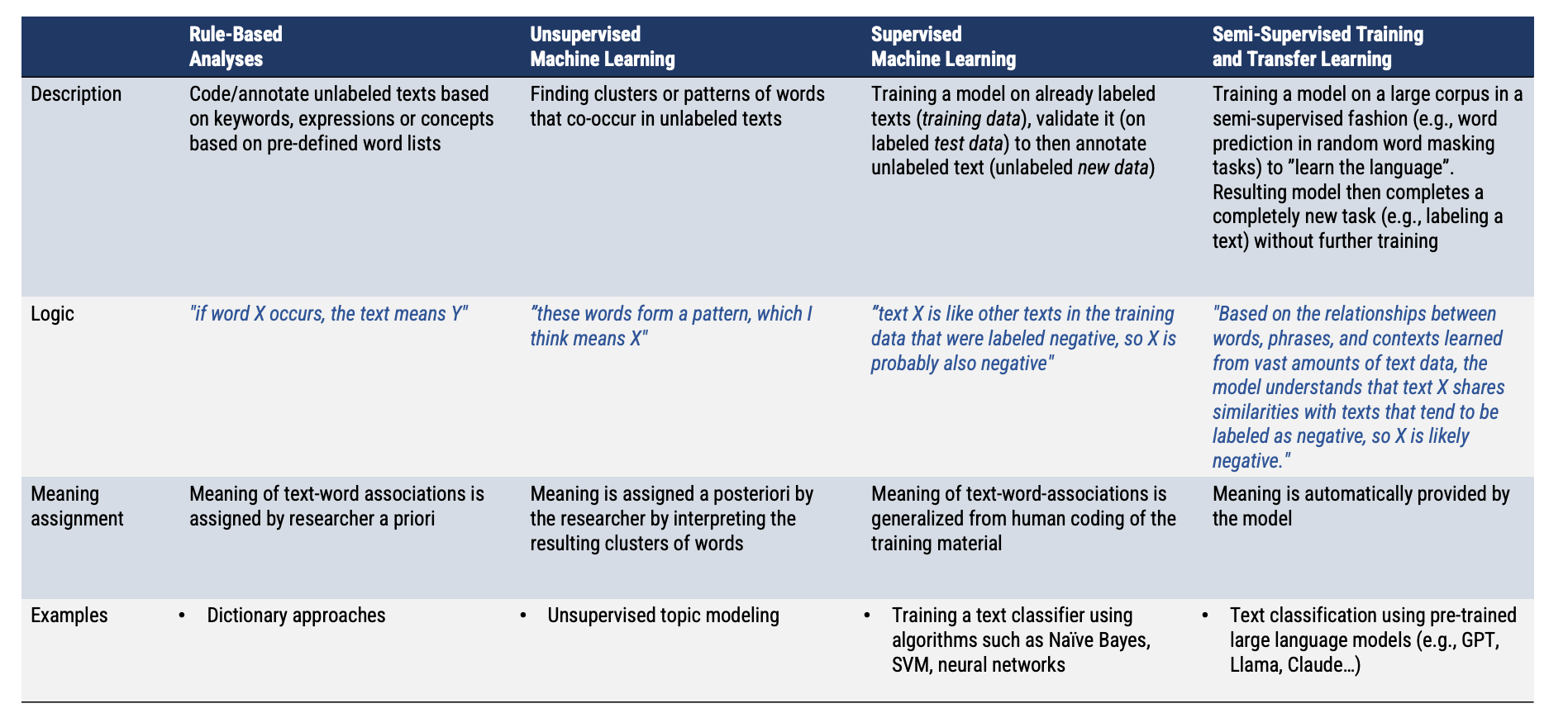
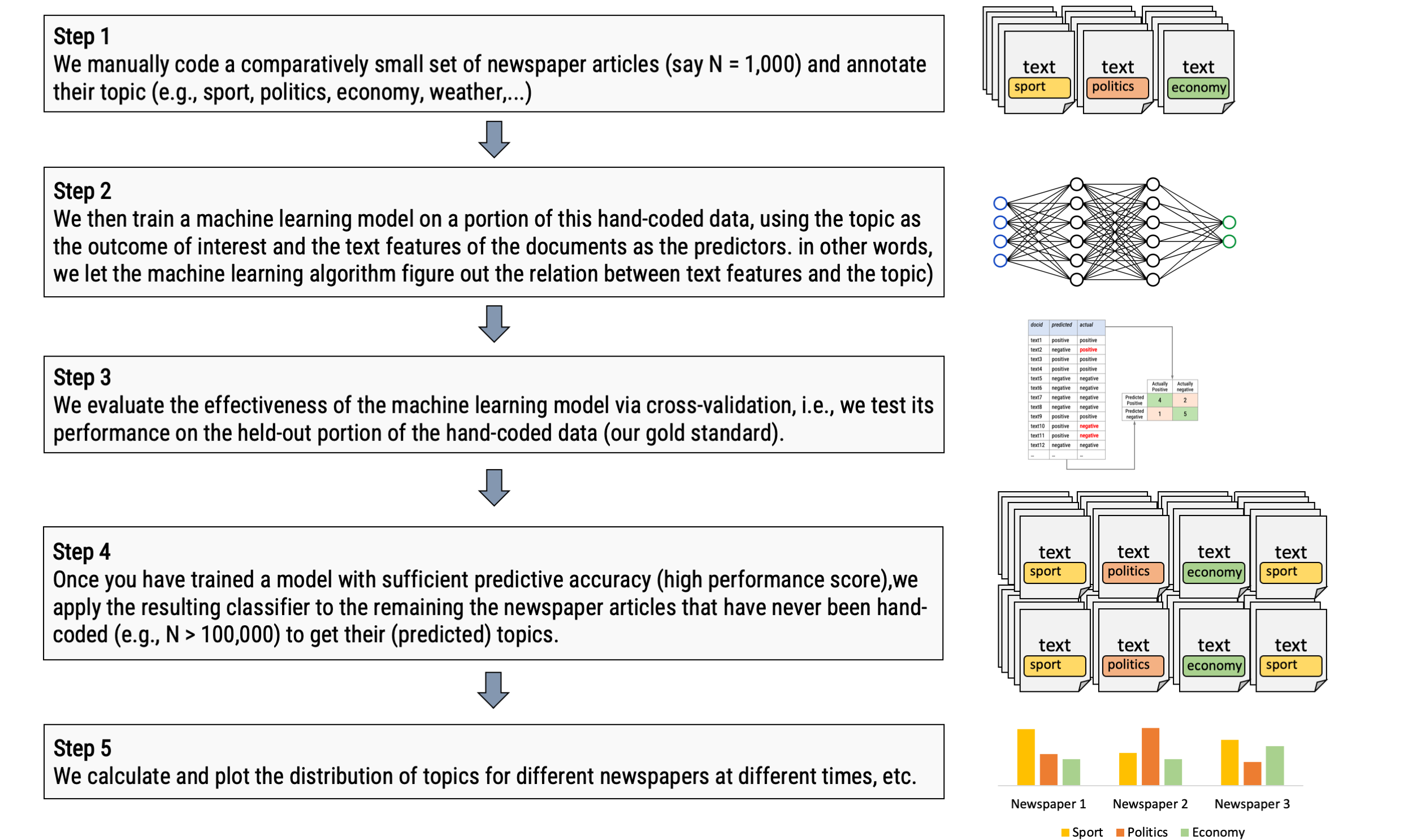
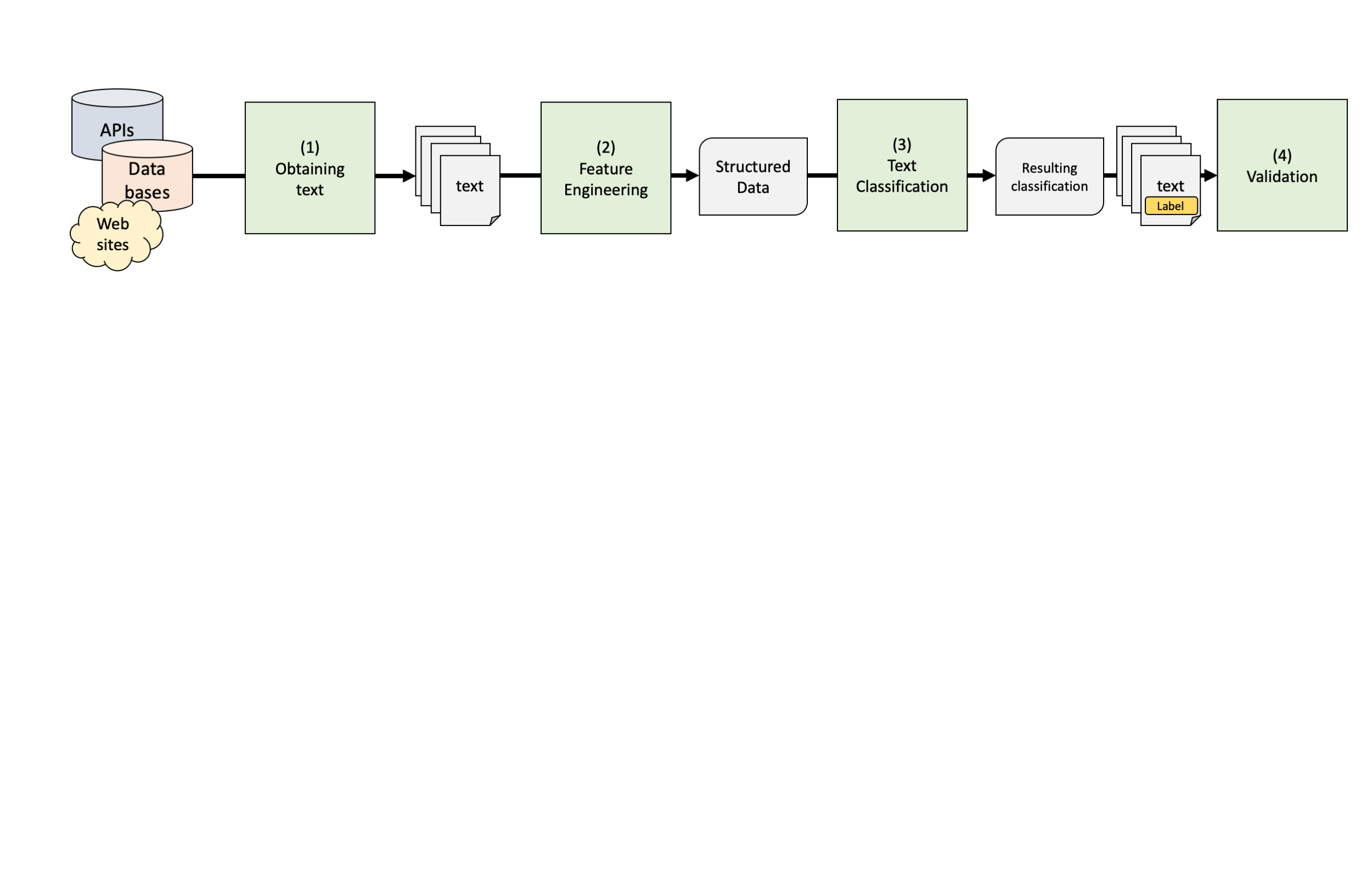
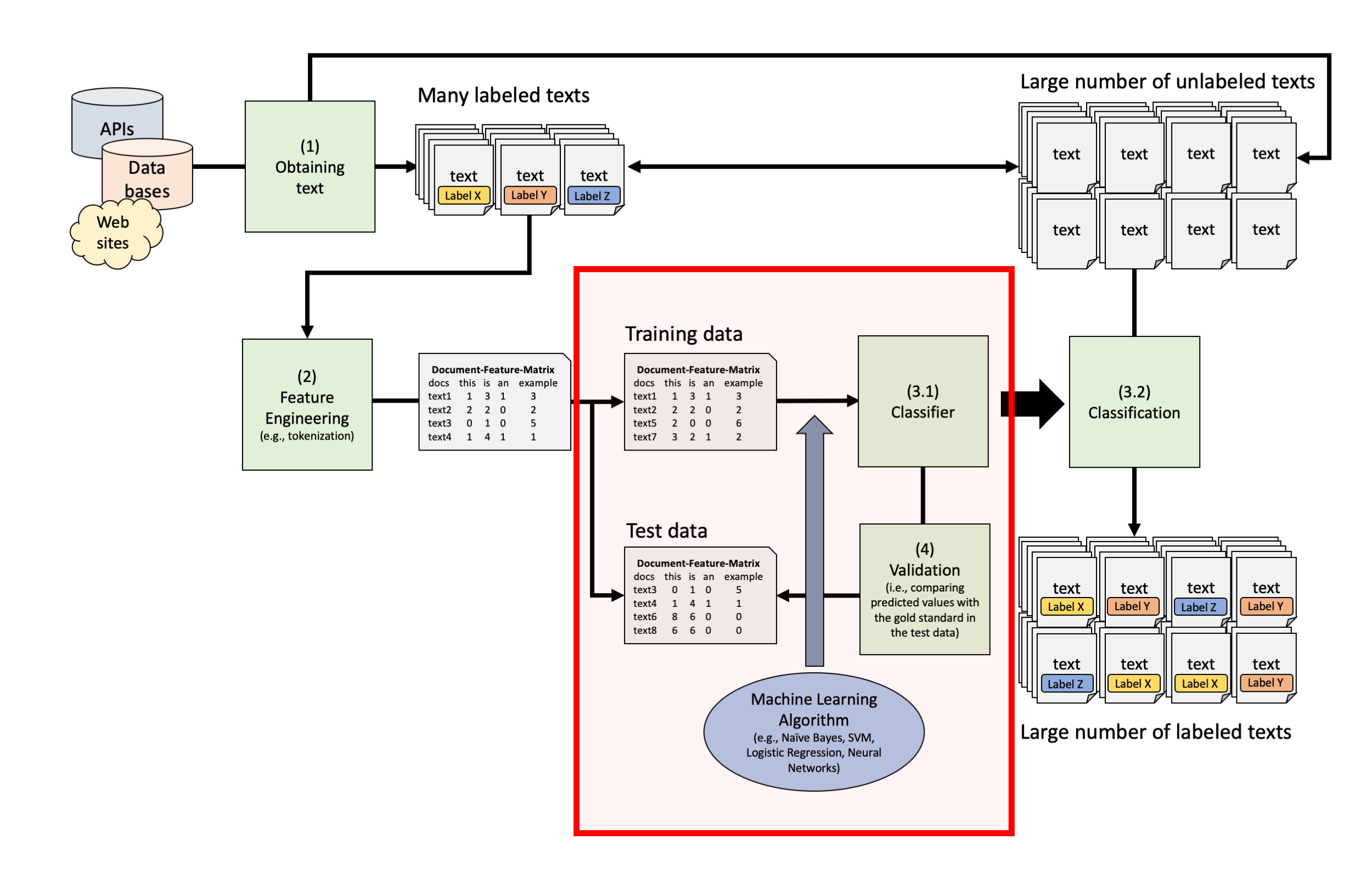
Describe the typical process used in supervised text classification.
Any supervised machine learning procedure to analyze text usually contains at least 4 steps:
One has to manually code a small set of documents for whatever variable(s) you care about (e.g., topics, sentiment, source,…).
One has to train a machine learning model on the hand-coded /gold-standard data, using the variable as the outcome of interest and the text features of the documents as the predictors.
One has to evaluate the effectiveness of the machine learning model via cross-validation. This means one has to test the model test on new (held-out) data.
Once one has trained a model with sufficient predictive accuracy, precision and recall, one can apply the model to more documents that have never been hand-coded or use it for the purpose it was designed for (e.g., a spam filter detection software)
![]()