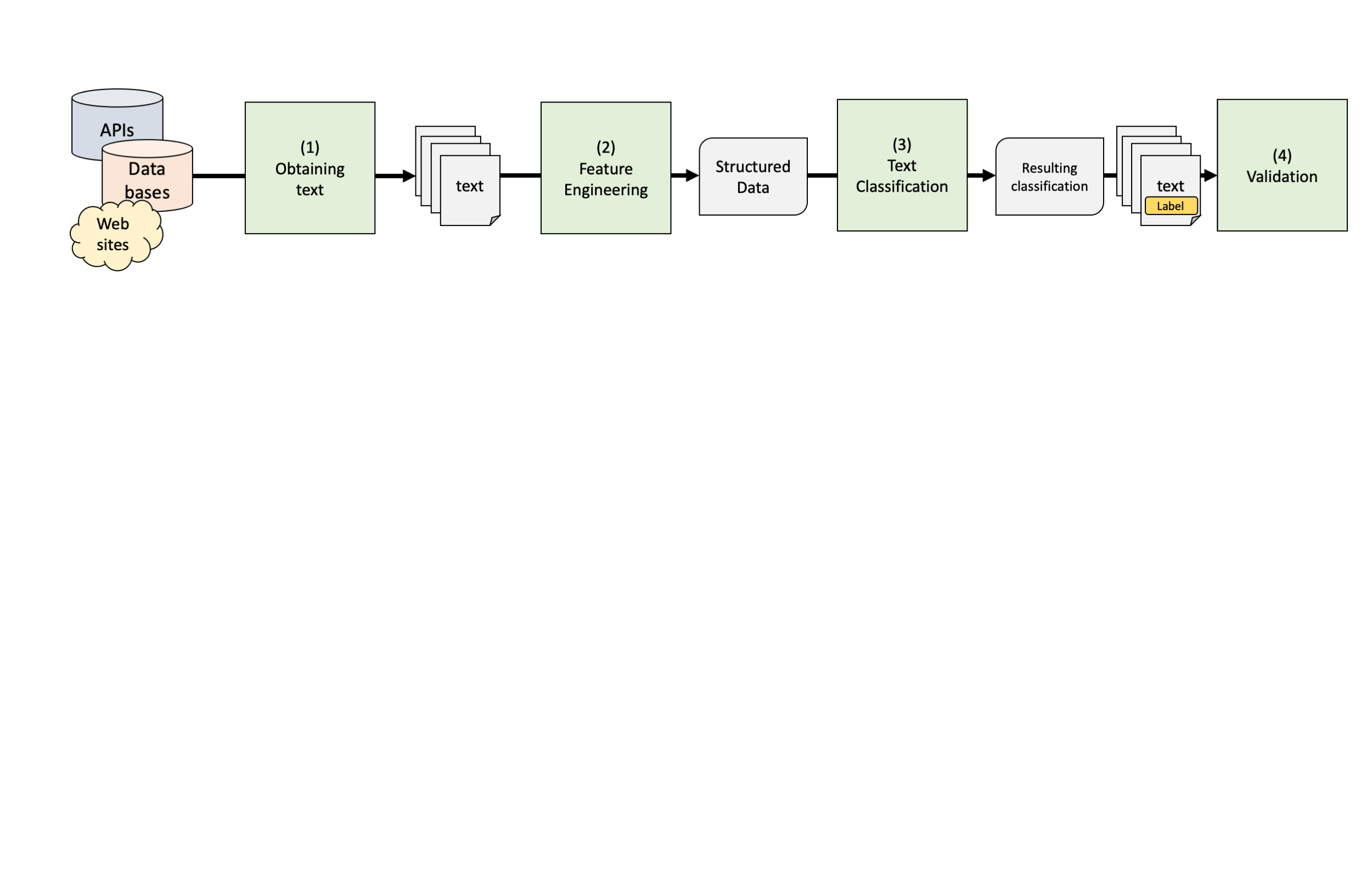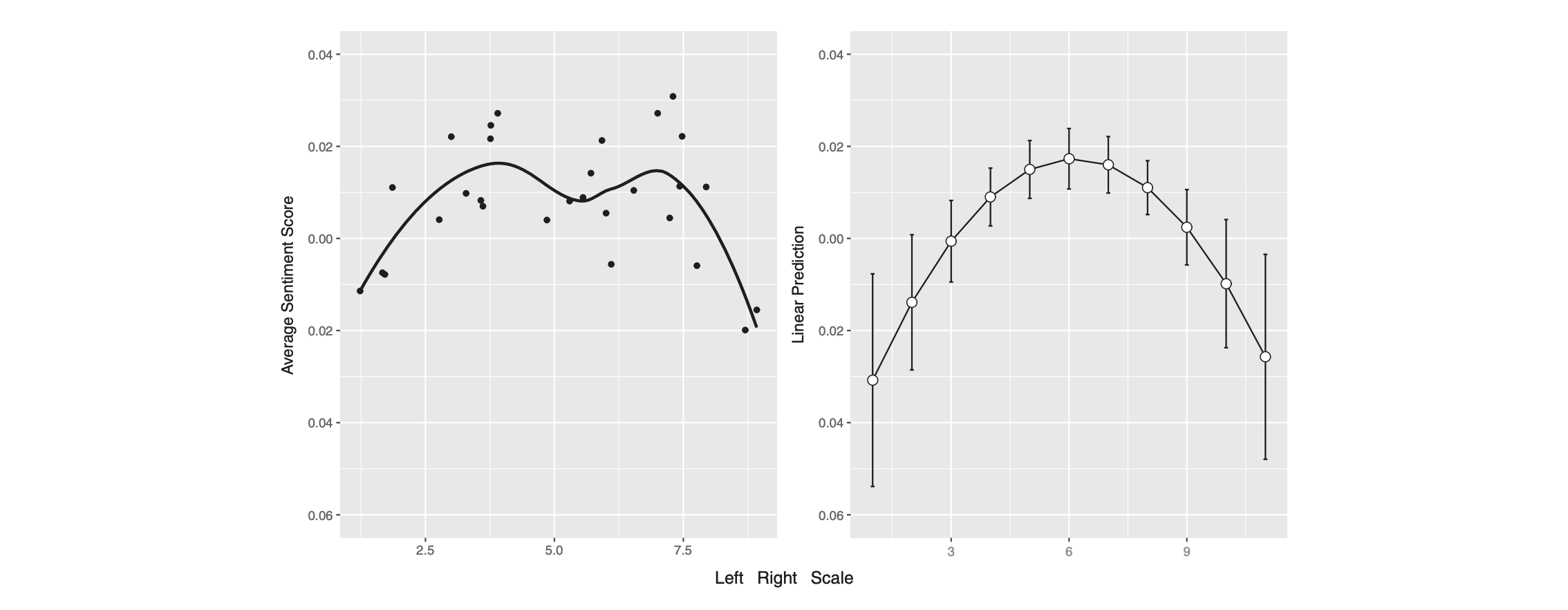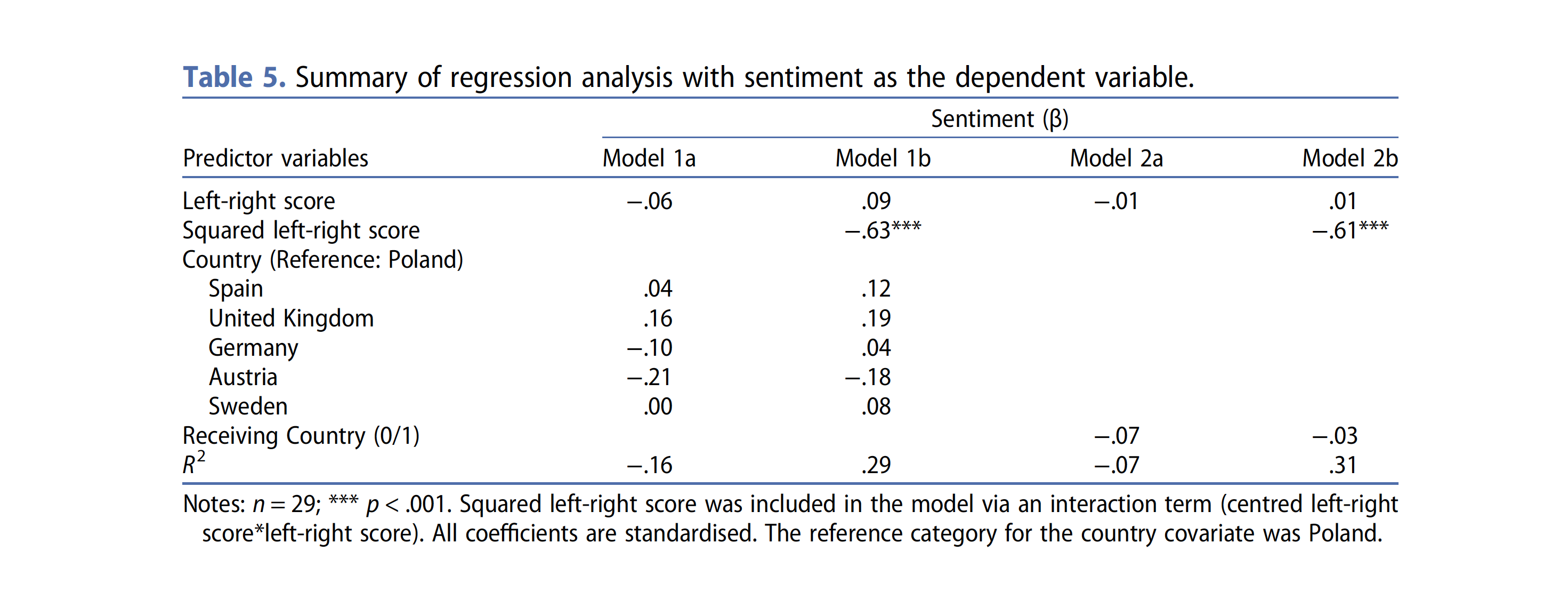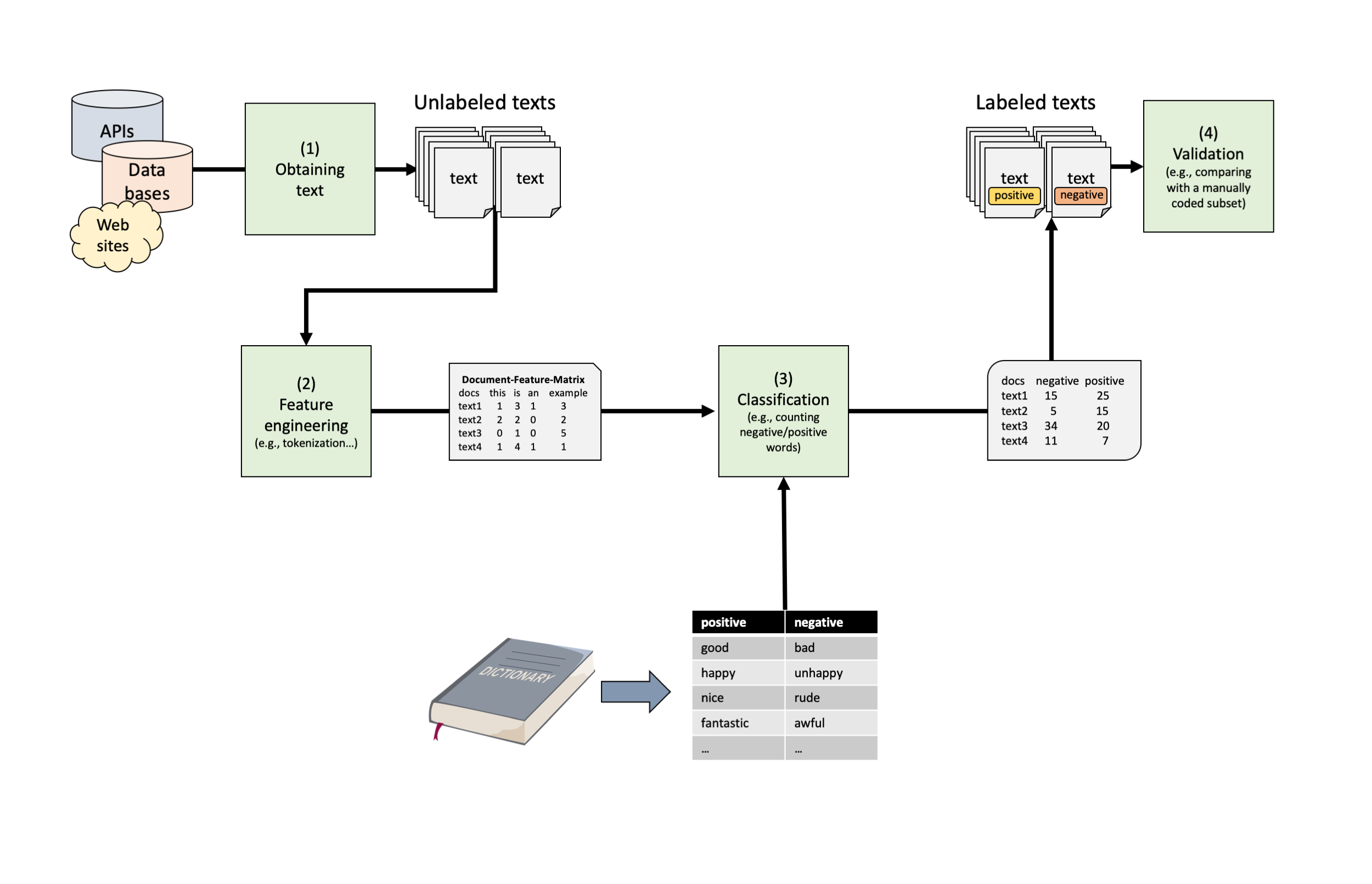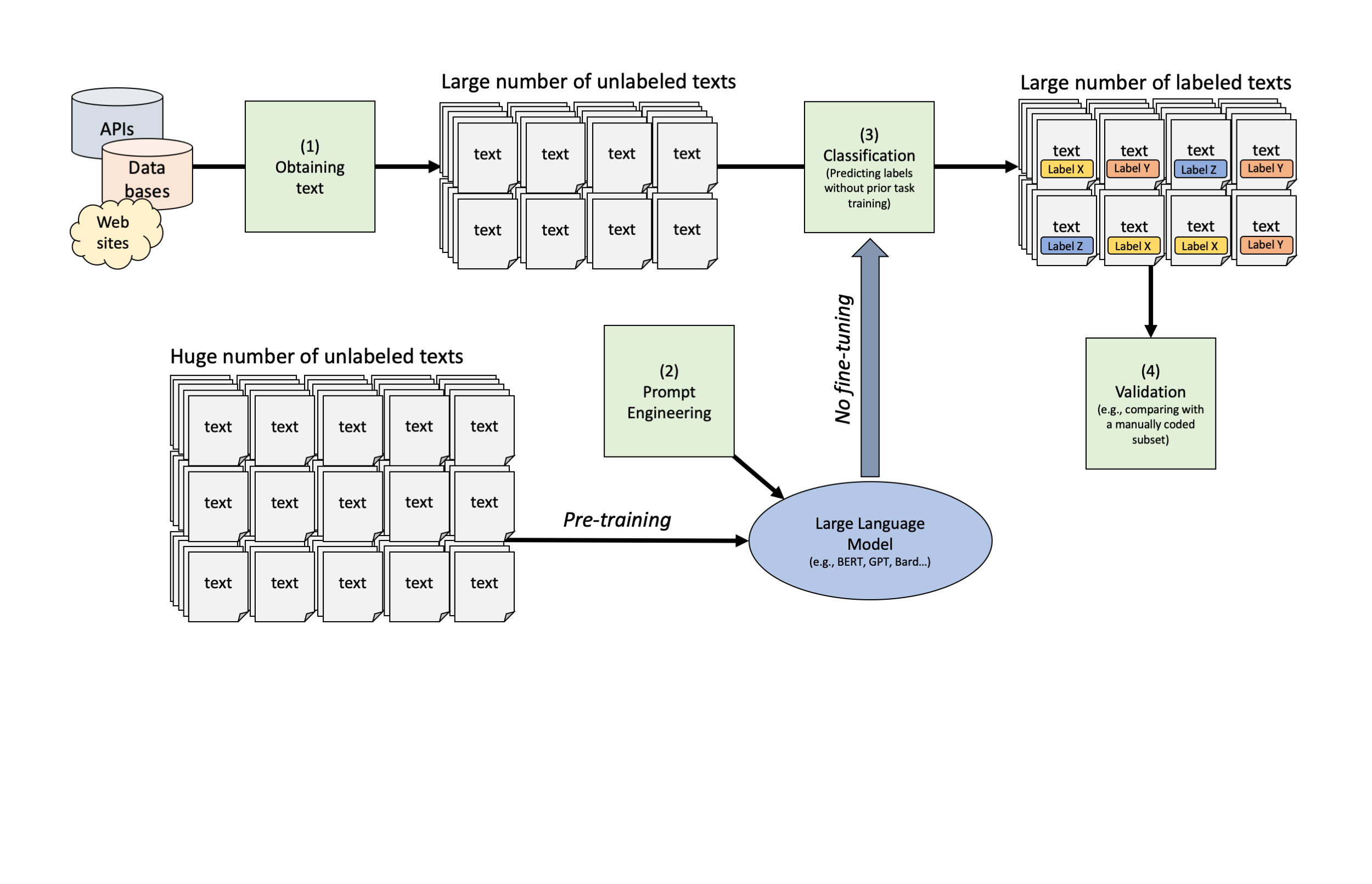
library(tidyllm)
llm_message("Is there a man in this image?
Only use 30 words in your answer.",
.imagefile = "img/fox_news.jpeg") |>
chat(ollama(.model = "llava", .temperature = 0)) |>
get_reply() |>
strwrap(width = 40) |>
paste(collapse = "\n") |>
cat()Yes, there is a man in the image. He
appears to be a news anchor or
reporter, as he is sitting at a news
desk with a background that suggests a
television studio setting. The man is
dressed professionally and seems to be
presenting or discussing a topic
related to the graphic displayed on the
screen behind him.